LLVM 中的自动向量化¶
LLVM 有两个向量化器:循环向量化器,它作用于循环;以及 SLP 向量化器。这些向量化器侧重于不同的优化机会,并使用不同的技术。SLP 向量化器将代码中找到的多个标量合并为向量,而循环向量化器则扩展循环中的指令以对多个连续迭代进行操作。
循环向量化器和 SLP 向量化器默认都已启用。
循环向量化器¶
用法¶
循环向量化器默认启用,但可以通过 clang 使用命令行标志禁用
$ clang ... -fno-vectorize file.c
命令行标志¶
循环向量化器使用成本模型来决定最佳向量化因子和展开因子。但是,向量化器的用户可以强制向量化器使用特定值。“clang” 和 “opt” 都支持以下标志。
用户可以使用命令行标志 “-force-vector-width” 控制向量化 SIMD 宽度。
$ clang -mllvm -force-vector-width=8 ...
$ opt -loop-vectorize -force-vector-width=8 ...
用户可以使用命令行标志 “-force-vector-interleave” 控制展开因子。
$ clang -mllvm -force-vector-interleave=2 ...
$ opt -loop-vectorize -force-vector-interleave=2 ...
Pragma 循环提示指令¶
#pragma clang loop 指令允许为后续的 for、while、do-while 或 c++11 基于范围的 for 循环指定循环向量化提示。该指令允许启用或禁用向量化和交错。向量宽度以及交错计数也可以手动指定。以下示例显式启用向量化和交错
#pragma clang loop vectorize(enable) interleave(enable)
while(...) {
...
}
以下示例通过指定向量宽度和交错计数来隐式启用向量化和交错
#pragma clang loop vectorize_width(2) interleave_count(2)
for(...) {
...
}
有关详细信息,请参阅 Clang 语言扩展。
诊断¶
许多循环无法向量化,包括具有复杂控制流、不可向量化类型和不可向量化调用的循环。循环向量化器生成优化备注,可以使用命令行选项查询这些备注,以识别和诊断被循环向量化器跳过的循环。
使用以下命令启用优化备注
-Rpass=loop-vectorize 标识已成功向量化的循环。
-Rpass-missed=loop-vectorize 标识向量化失败的循环,并指示是否指定了向量化。
-Rpass-analysis=loop-vectorize 标识导致向量化失败的语句。如果此外还提供了 -fsave-optimization-record,则可能会列出向量化失败的多个原因(此行为将来可能会更改)。
考虑以下循环
#pragma clang loop vectorize(enable)
for (int i = 0; i < Length; i++) {
switch(A[i]) {
case 0: A[i] = i*2; break;
case 1: A[i] = i; break;
default: A[i] = 0;
}
}
命令行 -Rpass-missed=loop-vectorize 打印备注
no_switch.cpp:4:5: remark: loop not vectorized: vectorization is explicitly enabled [-Rpass-missed=loop-vectorize]
命令行 -Rpass-analysis=loop-vectorize 指示 switch 语句无法向量化。
no_switch.cpp:4:5: remark: loop not vectorized: loop contains a switch statement [-Rpass-analysis=loop-vectorize]
switch(A[i]) {
^
要确保生成行号和列号,请包含命令行选项 -gline-tables-only 和 -gcolumn-info。有关详细信息,请参阅 Clang 用户手册
特性¶
LLVM 循环向量化器具有许多特性,使其能够向量化复杂的循环。
循环次数未知的循环¶
循环向量化器支持循环次数未知的循环。在下面的循环中,迭代的 start 和 finish 点是未知的,并且循环向量化器具有一种机制来向量化不从零开始的循环。在此示例中,“n” 可能不是向量宽度的倍数,并且向量化器必须将最后几次迭代作为标量代码执行。保留循环的标量副本会增加代码大小。
void bar(float *A, float* B, float K, int start, int end) {
for (int i = start; i < end; ++i)
A[i] *= B[i] + K;
}
指针的运行时检查¶
在下面的示例中,如果指针 A 和 B 指向连续的地址,则向量化代码是非法的,因为 A 的某些元素将在从数组 B 读取之前被写入。
一些程序员使用 “restrict” 关键字来通知编译器指针是不相交的,但在我们的示例中,循环向量化器无法知道指针 A 和 B 是唯一的。循环向量化器通过放置代码来处理此循环,该代码在运行时检查数组 A 和 B 是否指向不相交的内存位置。如果数组 A 和 B 重叠,则执行循环的标量版本。
void bar(float *A, float* B, float K, int n) {
for (int i = 0; i < n; ++i)
A[i] *= B[i] + K;
}
归约¶
在此示例中,sum 变量被循环的连续迭代使用。通常,这将阻止向量化,但向量化器可以检测到 “sum” 是一个归约变量。变量 “sum” 变为整数向量,并且在循环结束时,数组的元素被加在一起以创建正确的结果。我们支持许多不同的归约操作,例如加法、乘法、异或、与和或。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i] + 5;
return sum;
}
当使用 -ffast-math 时,我们支持浮点归约运算。
归纳¶
在此示例中,归纳变量 i 的值被保存到数组中。循环向量化器知道要向量化归纳变量。
void bar(float *A, int n) {
for (int i = 0; i < n; ++i)
A[i] = i;
}
If 转换¶
循环向量化器能够“展平”代码中的 IF 语句并生成单个指令流。循环向量化器支持最内层循环中的任何控制流。最内层循环可能包含 IF、ELSE 甚至 GOTO 的复杂嵌套。
int foo(int *A, int *B, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
if (A[i] > B[i])
sum += A[i] + 5;
return sum;
}
指针归纳变量¶
此示例使用标准 c++ 库的 “accumulate” 函数。此循环使用 C++ 迭代器(指针),而不是整数索引。循环向量化器检测指针归纳变量,并且可以向量化此循环。此特性非常重要,因为许多 C++ 程序使用迭代器。
int baz(int *A, int n) {
return std::accumulate(A, A + n, 0);
}
反向迭代器¶
循环向量化器可以向量化向后计数的循环。
void foo(int *A, int n) {
for (int i = n; i > 0; --i)
A[i] +=1;
}
分散/收集¶
循环向量化器可以向量化变成一系列标量指令的代码,这些指令分散/收集内存。
void foo(int * A, int * B, int n) {
for (intptr_t i = 0; i < n; ++i)
A[i] += B[i * 4];
}
在许多情况下,成本模型会告知 LLVM 这没有好处,并且 LLVM 仅在使用 “-mllvm -force-vector-width=#” 强制执行时才向量化此类代码。
混合类型的向量化¶
循环向量化器可以向量化具有混合类型的程序。向量化器成本模型可以估计类型转换的成本,并决定向量化是否有利可图。
void foo(int *A, char *B, int n) {
for (int i = 0; i < n; ++i)
A[i] += 4 * B[i];
}
全局结构别名分析¶
对全局结构的访问也可以向量化,并使用别名分析来确保访问不产生别名。运行时检查也可以添加到对结构成员的指针访问中。
支持许多变体,但一些依赖于未定义行为被忽略(如其他编译器所做的那样)的变体仍然未被向量化。
struct { int A[100], K, B[100]; } Foo;
void foo() {
for (int i = 0; i < 100; ++i)
Foo.A[i] = Foo.B[i] + 100;
}
函数调用的向量化¶
循环向量化器可以向量化内部数学函数。请参阅下表,了解这些函数的列表。
pow |
exp |
exp2 |
sin |
cos |
sqrt |
log |
log2 |
log10 |
fabs |
floor |
ceil |
fma |
trunc |
nearbyint |
fmuladd |
请注意,如果库调用访问外部状态(例如 “errno”),则优化器可能无法向量化与这些内部函数对应的数学库函数。为了更好地优化 C/C++ 数学库函数,请使用 “-fno-math-errno”。
循环向量化器了解目标上的特殊指令,并将向量化包含映射到这些指令的函数调用的循环。例如,如果 SSE4.1 roundps 指令可用,则以下循环将在 Intel x86 上向量化。
void foo(float *f) {
for (int i = 0; i != 1024; ++i)
f[i] = floorf(f[i]);
}
许多这些数学函数只有在文件已使用指定的提供该数学函数的向量实现的 target vector library 构建时才是可向量化的。使用 clang,这由 “-fveclib” 命令行选项处理,其中一个向量库为:“accelerate,libmvec,massv,svml,sleef,darwin_libsystem_m,armpl,amdlibm”
$ clang ... -fno-math-errno -fveclib=libmvec file.c
向量化期间的部分展开¶
现代处理器具有多个执行单元,只有包含高度并行性的程序才能充分利用机器的整个宽度。循环向量化器通过执行循环的部分展开来提高指令级并行性 (ILP)。
在下面的示例中,整个数组被累加到变量 “sum” 中。这是低效的,因为处理器只能使用单个执行端口。通过展开代码,循环向量化器允许同时使用两个或多个执行端口。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i];
return sum;
}
循环向量化器使用成本模型来决定何时展开循环是有利可图的。展开循环的决定取决于寄存器压力和生成的代码大小。
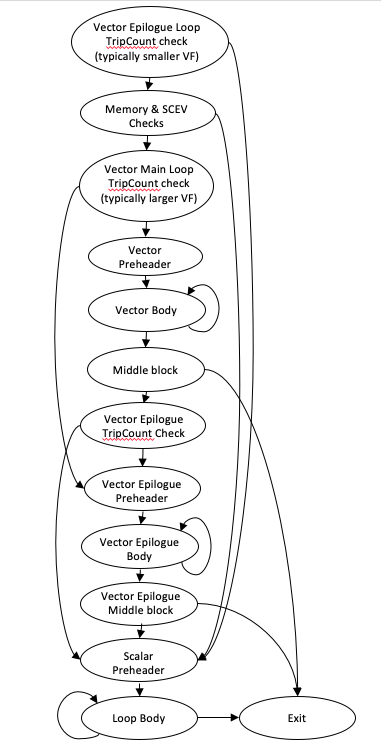
尾声向量化¶
当向量化循环时,如果循环次数未知或它不能均匀地除以向量化和展开因子,则通常需要标量余数(尾声)循环来执行循环的尾部迭代。当向量化和展开因子很大时,循环次数较小的循环可能会最终将大部分时间花费在标量(而不是向量)代码中。为了解决这个问题,内部循环向量化器通过一项特性得到增强,该特性允许它使用向量化和展开因子组合来向量化尾声循环,这使得小循环次数的循环更有可能仍然在向量化代码中执行。下图显示了具有运行时检查的典型尾声向量化循环的 CFG。如图所示,控制流的结构方式避免了重复运行时指针检查,并优化了循环次数非常小的循环的路径长度。
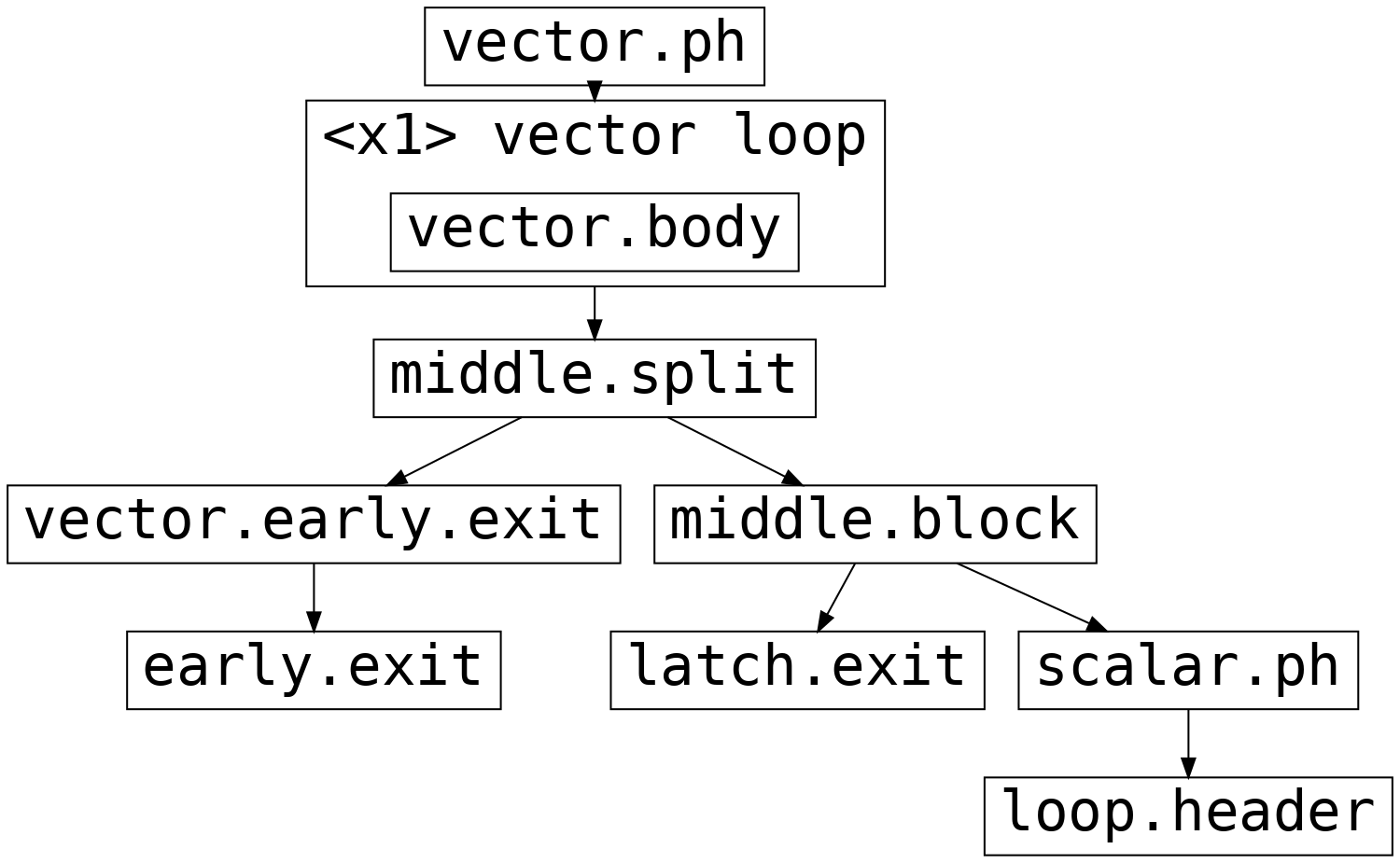
提前退出向量化¶
当向量化具有单个提前退出的循环时,提前退出后的循环块将被谓词化,并且向量循环将始终通过锁存器退出。如果已采取提前退出,则向量循环的后继块(下面的 middle.split)通过中间块(下面的 vector.early.exit)分支到提前退出块。此中间块负责计算在提前退出块中使用的循环定义变量的任何退出值。否则,middle.block 在来自锁存器或标量余数循环的退出块之间进行选择。
性能¶
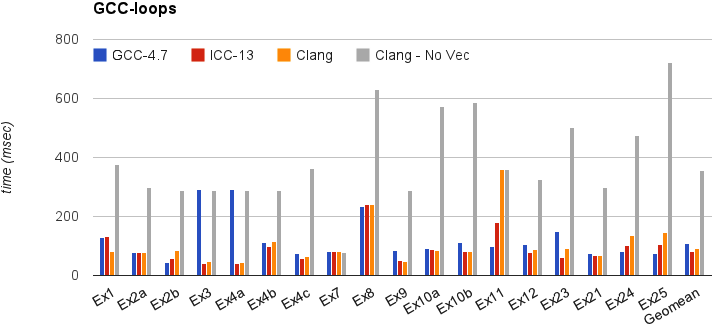
本节显示了 Clang 在一个简单基准测试上的执行时间:gcc-loops。此基准测试是来自 Dorit Nuzman 的 GCC 自动向量化 页面 的循环集合。
下图比较了 GCC-4.7、ICC-13 和 Clang-SVN 在 -O3 下启用和禁用循环向量化的情况,针对 “corei7-avx” 进行了调整,并在 Sandybridge iMac 上运行。Y 轴显示时间,单位为毫秒。数值越低越好。最后一列显示所有内核的几何平均值。
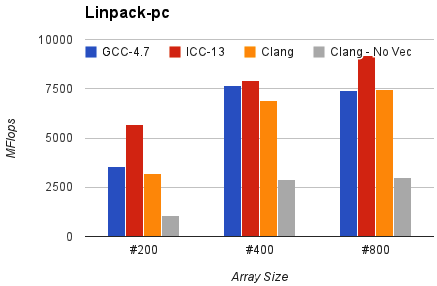
以及具有相同配置的 Linpack-pc。结果是 Mflops,数值越高越好。
正在进行的开发方向¶
- 向量化计划
建模 LLVM 循环向量化器的过程并升级其基础设施。
SLP 向量化器¶
详情¶
SLP 向量化(也称为超字级并行)的目标是将相似的独立指令组合成向量指令。内存访问、算术运算、比较运算、PHI 节点都可以使用此技术进行向量化。
例如,以下函数对其输入 (a1, b1) 和 (a2, b2) 执行非常相似的操作。基本块向量化器可以将这些操作组合成向量操作。
void foo(int a1, int a2, int b1, int b2, int *A) {
A[0] = a1*(a1 + b1);
A[1] = a2*(a2 + b2);
A[2] = a1*(a1 + b1);
A[3] = a2*(a2 + b2);
}
SLP 向量化器自底向上、跨基本块处理代码,以搜索要组合的标量。
用法¶
SLP 向量化器默认启用,但可以通过 clang 使用命令行标志禁用
$ clang -fno-slp-vectorize file.c