向量化计划¶
摘要¶
向量化转换可能相当复杂,涉及几种可能的替代方案,特别是对于外层循环 [1],也可能对于最内层循环。这些替代方案可能对性能产生重大影响,包括正面和负面影响。因此,采用成本模型来识别最佳替代方案,包括完全避免任何转换的替代方案。
向量化计划是一个显式模型,用于描述向量化候选对象。它既用于优化候选对象,包括可靠地估计其成本,也用于执行其最终到 IR 的转换。这有助于处理多个向量化候选对象。
当前状态¶
VPlan 目前用于驱动 LoopVectorize 中的代码生成。VPlan 在所有基于成本的决策和大多数与合法性相关的决策做出后构建。由于配方之间的 def-use 链现在在 VPlan 中完全建模,因此基于 VPlan 的分析和转换用于简化和模块化向量化过程 [10]。这些包括以下转换:
合法化初始 VPlan,例如,通过为归约和交错组引入专门的配方。
优化合法化的 VPlan,例如,通过删除冗余配方或引入 active-lane-masks。
应用特定于展开和向量化因子的优化,例如,基于 VF 和 UF 删除后沿以迭代向量循环。
有关当前转换管道的概述,请参阅 图 3。
请注意,某些合法性检查已经在 VPlan 中完成,包括检查固定顺序的递归的所有用户是否可以重新排序。这被实现为 VPlan 到 VPlan 的转换,它可以应用有效的重新排序,或者退出并将 VPlan 标记为无效。
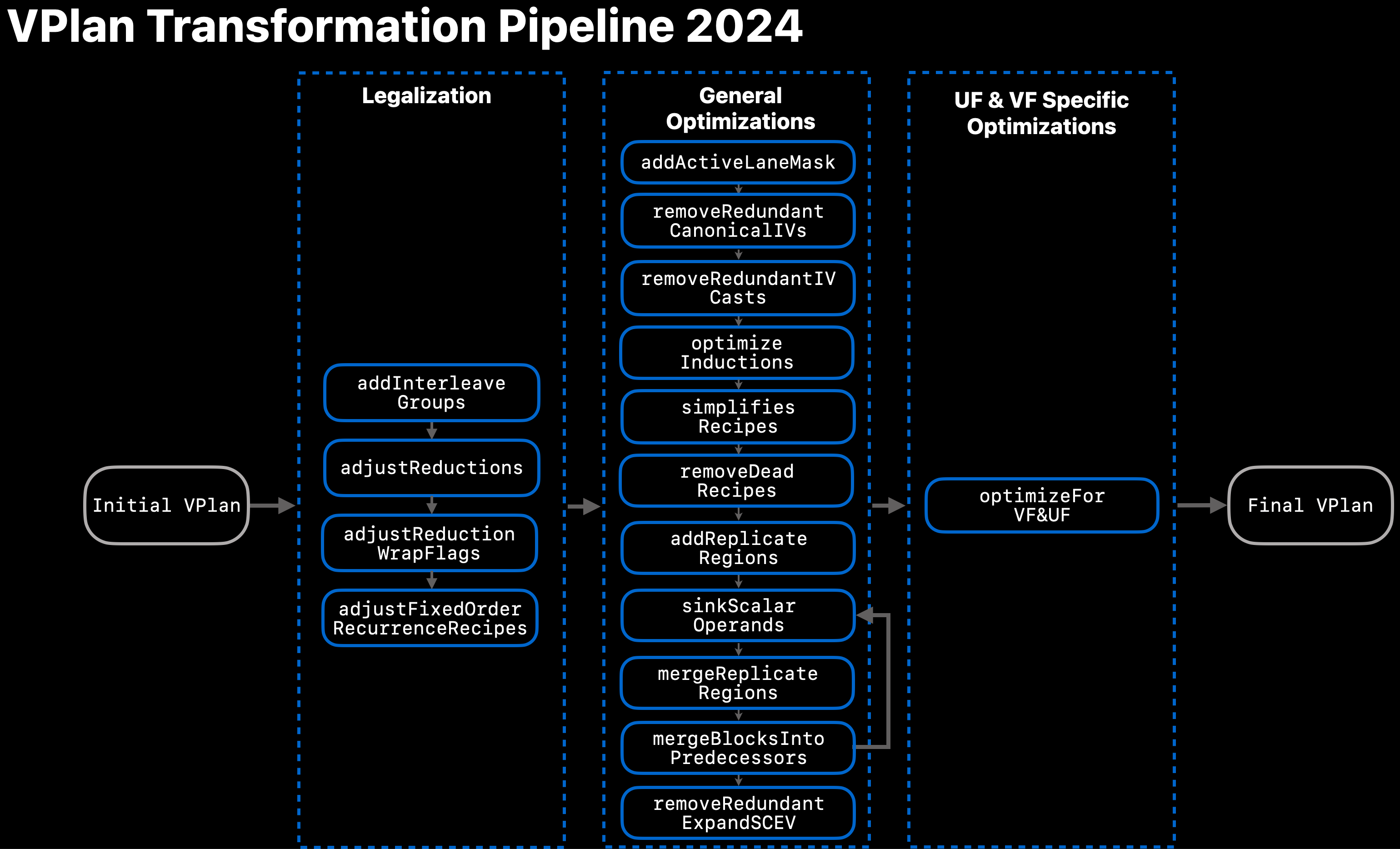
图 3 2024 年的 VPlan 转换管道¶
VPlan 目前对完整的向量循环以及向量化骨架的其他部分进行建模。有关 VPlan 覆盖范围的概述,请参阅 图 4。
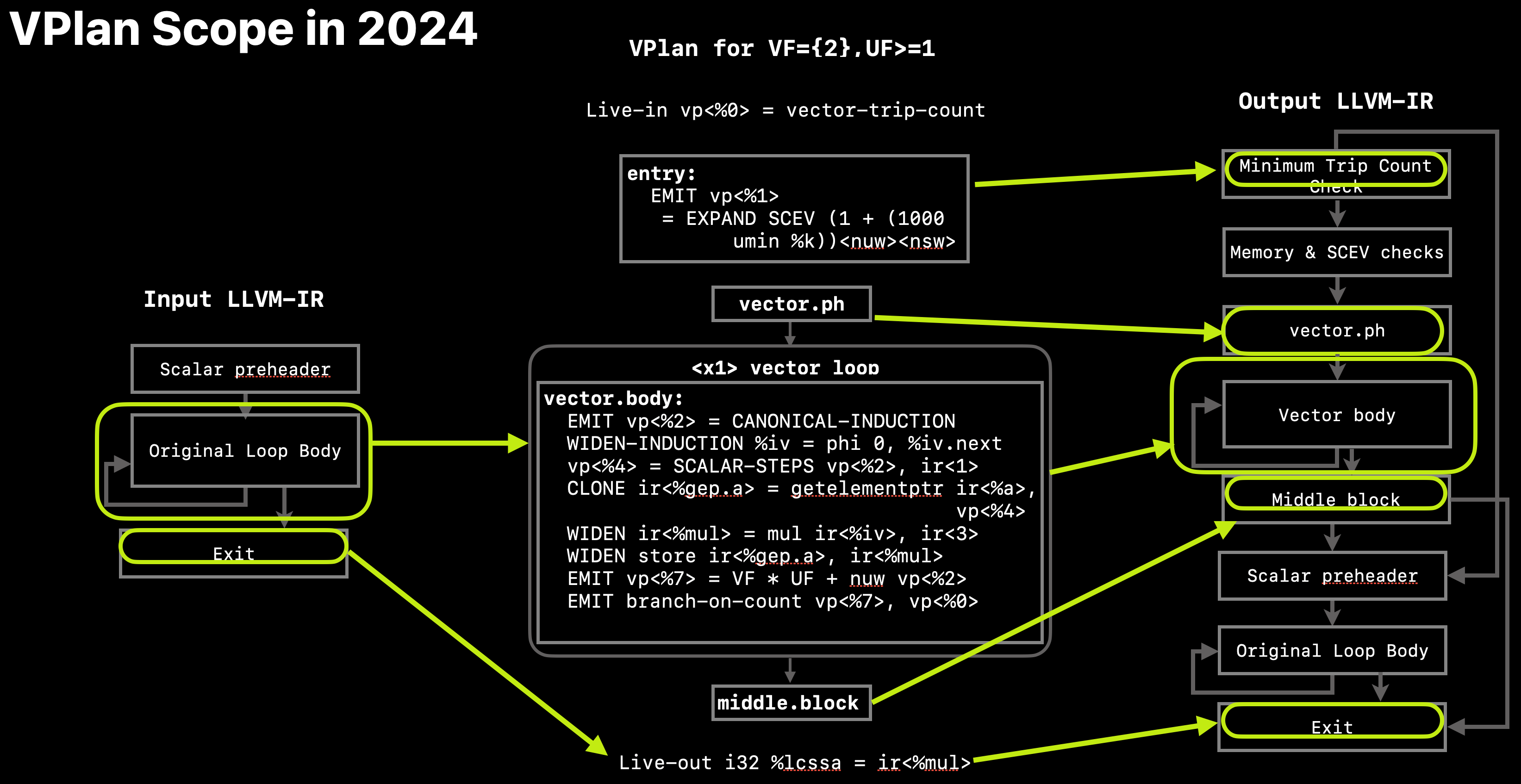
图 4 2024 年 VPlan 中建模的范围¶
高层设计¶
向量化工作流程¶
基于 VPlan 的向量化涉及三个主要步骤,采用“基于场景的方法”进行向量化规划
合法性步骤:检查循环是否可以合法地向量化;如果可以,则编码约束和工件。
计划步骤
遵循合法性步骤 1 采取的约束和决策构建初始 VPlan,并计算其成本。
对 VPlan 应用优化,可能会派生出额外的 VPlan。修剪成本相对较高的次优 VPlan。
执行步骤:实现最佳 VPlan。请注意,这是唯一修改 IR 的步骤。
设计指南¶
在下文中,“输入 IR”一词指的是馈入向量化器的代码,而“输出 IR”一词指的是由向量化器生成的代码。输出 IR 包含已根据循环向量化因子 (VF) 向量化或“加宽”的代码,和/或根据展开因子 (UF) 进行循环展开和 jamming 的代码。VPlan 的设计遵循几个高层指南
类似分析:构建和操作 VPlan 不得修改输入 IR。特别是,如果最佳选择是不进行任何向量化,则向量化过程在到达步骤 3 之前终止,并且编译应像未构建 VPlan 一样继续进行。
对齐成本与执行:每个 VPlan 必须支持成本估算和生成输出 IR 代码,以便成本估算可靠地评估要生成的代码。
支持向量化其他构造
有效地支持多个候选对象。特别是,与一系列可能的 VF 和 UF 相关的类似候选对象必须得到有效表示。需要有效支持潜在的版本控制。
支持向量化惯用法,例如交错的步幅加载或存储组。这是通过使用“配方”对输出指令序列进行建模来实现的,“配方”负责计算其成本并生成其代码。
封装单入口单出口区域 (SESE)。在向量化期间,可能需要对这些区域进行例如谓词化和线性化,或复制 VF*UF 次以处理标量化和谓词化的指令。内层循环也建模为 SESE 区域。
支持指令级分析和转换,作为计划步骤 2.b 的一部分:在向量化期间,可能需要遍历、移动、替换为其他指令或创建指令。例如,向量惯用法检测和形成涉及搜索和优化指令模式。
定义¶
VPlan 的低层设计包括以下类。
- LoopVectorizationPlanner:
LoopVectorizationPlanner 旨在处理循环或循环嵌套的向量化。它可以构建、优化和丢弃一个或多个 VPlan,每个 VPlan 对向量化循环或循环嵌套的不同方式进行建模。一旦确定了最佳 VPlan,包括最佳 VF 和 UF,此 VPlan 将驱动输出 IR 的生成。
- VPlan:
给定输入 IR 循环或循环嵌套的向量化候选对象的模型。此候选对象使用分层 CFG 表示。VPlan 支持估计成本并驱动其表示的输出 IR 代码的生成。
- 分层 CFG:
控制流图,其节点是基本块或分层 CFG。分层 CFG 数据结构类似于 Tile Tree [5],其中跨 Tile 边缘被提升以连接 Tile 而不是原始基本块,如 Sharir [6] 中所述,从而促进 Tile 封装。术语 Region 和 Block 而不是 Tile [5] 使用,以避免与循环 tiling 混淆。
- VPBlockBase:
分层 CFG 的构建块。VPBasicBlock 和 VPRegionBlock 的纯虚基类,见下文。VPBlockBase 模拟与其他 VPBlock 的分层控制流关系。请注意,与 IR BasicBlock 相比,VPBlockBase 直接模拟其控制流后继和前任,而不是通过终止符分支或通过“使用”VPBlockBase 的前任分支。
- VPBasicBlock:
VPBasicBlock 是 VPBlockBase 的子类,并充当分层 CFG 的叶子。它表示输出 IR 指令的序列,这些指令将连续出现在输出 IR 基本块中。此基本块的指令源自一个或多个 VPBasicBlock。VPBasicBlock 包含零个或多个 VPRecipe 的序列,这些序列对输出 IR 指令的成本和生成进行建模。
- VPRegionBlock:
VPRegionBlock 是 VPBlockBase 的子类。它对 VPBasicBlock 和 VPRegionBlock 的集合进行建模,这些集合形成输出 IR CFG 的 SESE 子图。VPRegionBlock 可以指示在生成输出 IR 时,其内容将被复制恒定次数,有效地表示具有恒定 trip-count 的循环,该循环将被完全展开。这用于支持具有单个模型和多个候选 VF 和 UF 的标量化和谓词化指令。
- VPRecipeBase:
纯虚基类,对一个或多个输出 IR 指令的序列进行建模,可能基于一个或多个输入 IR 指令。这些输入 IR 指令被称为配方的“成分”。配方可以指定如何转换其成分以生成输出 IR 指令;例如,克隆一次、复制多次或根据选定的 VF 加宽。
- VPValue:
VPlan 的 def-use 关系类层次结构的基类。实例化后,它在 VPlan 中对常量或 live-in Value 进行建模。它有用户,类型为 VPUser,但没有操作数。
- VPUser:
VPUser 表示使用多个 VPValue 作为操作数的实体。VPUser 在某些方面类似于 LLVM 的 User 类。
- VPDef:
VPDef 表示定义零个、一个或多个 VPValue 的实体。它用于对 VPlan 中的配方可以定义多个 VPValue 的事实进行建模。
- VPInstruction:
VPInstruction 是一种配方,其特征是单个操作码和可选标志,不包含成分或其他元数据。VPInstruction 还使用惯用操作扩展了 LLVM IR 的操作码,这些操作丰富了向量化器的语义。
- VPTransformState:
存储用于生成输出 IR 的信息,从 LoopVectorizationPlanner 传递到其选定的 VPlan 以供执行,并用于将其他信息向下传递到 VPBlock 和 VPRecipe。
规划过程和 VPlan 路线图¶
将循环向量化器转换为使用 VPlan 遵循分阶段方法。首先,VPlan 仅用于记录最终向量化决策并执行它们:分层 CFG 对计划的控制流进行建模,配方捕获基本块内部做出的决策。目前,VPlan 也用作做出这些决策的基础,有效地将它们变成一系列 VPlan 到 VPlan 的算法。最后,VPlan 将支持规划过程本身,包括用于做出这些决策的基于成本的分析,以完全支持组合和迭代决策制定。
某些决策是循环中指令局部的,例如是否将其加宽为向量指令或复制它,保持生成的指令在原位。然而,其他决策涉及移动指令、用其他指令替换它们和/或引入新指令。例如,强制转换可能会沉降到后面的指令之后并被加宽以处理一阶递归;步幅收集或分散的交错组可以有效地移动到一个位置,在那里它们被 shuffle 和通用的宽向量加载或存储替换;可能会引入新指令来计算掩码、shuffle 向量的元素以及将标量值打包到向量中或反之亦然。
为了使 VPlan 支持做出指令级决策和分析,它需要对相关指令及其 def/use 关系进行建模。这也遵循分阶段方法:首先,计算掩码的新指令被建模为 VPInstruction,以及它们引起的 def/use 子图。这有效地在 VPlan 中对掩码进行建模,从而促进基于 VPlan 的谓词化。接下来,每个配方中用于在 VPlan 执行时生成其指令的逻辑,将通过将它们建模为 VPInstruction 来参与规划过程。最后,只有适用于指令组的逻辑将保留在配方中,例如交错组和可能具有协同成本的其他惯用法组。