LLVM 循环术语(和规范形式)¶
循环定义¶
循环是代码优化器的一个重要概念。在 LLVM 中,控制流图中的循环检测由 LoopInfo 完成。它基于以下定义。
循环是控制流图(CFG;其中节点代表基本块)中节点的子集,具有以下属性
诱导子图(它是包含循环内 CFG 中所有边的子图)是强连通的(每个节点都可以从所有其他节点到达)。
从子集外部到子集内部的所有边都指向同一个节点,称为头部。因此,头部支配循环中的所有节点(即,到达循环中任何节点的每条执行路径都必须经过头部)。
循环是具有这些属性的最大子集。也就是说,不能添加来自 CFG 的其他节点,使得诱导子图仍然是强连通的,并且头部保持不变。
在计算机科学文献中,这通常被称为自然循环。在 LLVM 中,更广义的定义称为 环。
术语¶
循环的定义附带一些附加术语
进入块(或循环前驱)是一个非循环节点,它有一条进入循环的边(必然是头部)。如果只有一个进入块,并且其唯一的边是指向头部的,则它也称为循环的前置头部。前置头部支配循环,但本身不是循环的一部分。
锁存器是一个循环节点,它有一条指向头部的边。
回边是从锁存器到头部的边。
退出边是从循环内部到循环外部节点的边。这种边的源节点称为退出块,其目标节点是出口块。

重要说明¶
此循环定义有一些值得注意的后果
一个节点最多可以是一个循环的头部。因此,循环可以通过其头部来识别。由于头部是进入循环的唯一入口,因此它可以被称为单入口多出口 (SEME) 区域。
对于从函数的入口不可达的基本块,循环的概念是未定义的。这遵循支配概念也是未定义的。
最小的循环由一个分支到自身的基本块组成。在这种情况下,该块同时是头部、锁存器(以及退出块,如果它有另一条边到不同的块)。一个没有分支到自身的基本块不被认为是循环,即使它是平凡地强连通的。

在这种情况下,头部、退出块和锁存器的角色都落到同一个节点。LoopInfo 将此报告为
$ opt input.ll -passes='print<loops>'
Loop at depth 1 containing: %for.body<header><latch><exiting>
循环可以相互嵌套。也就是说,一个循环的节点集可以是另一个具有不同循环头部的循环的子集。函数中的循环层次结构形成一个森林:每个顶层循环都是嵌套在其中的循环树的根。

两个循环不可能只共享它们的一些节点。两个循环要么是不相交的,要么一个嵌套在另一个内部。在下面的示例中,左侧和右侧子集都违反了最大性条件。只有两个集合的合并才被认为是循环。

两个逻辑循环也可能共享一个头部,但被 LLVM 视为单个循环
for (int i = 0; i < 128; ++i)
for (int j = 0; j < 128; ++j)
body(i,j);
这可能在 LLVM-IR 中表示如下。请注意,只有一个头部,因此只有一个循环。

LoopSimplify Pass 将检测循环并确保外部循环和内部循环有单独的头部。

CFG 中的环并不意味着存在循环。下面的示例显示了这样一个 CFG,其中没有支配环中所有其他节点的头部节点。这被称为不可约控制流。

术语可约性源于通过连续用单个节点替换以下三个基本结构之一来将 CFG 折叠成单个节点的能力:基本块的顺序执行、非循环条件分支(或开关)以及基本块自身循环。维基百科 有更正式的定义,它基本上是说每个环都有一个支配头部。
不可约控制流可能发生在循环嵌套的任何级别。也就是说,本身不包含任何循环的循环在其主体中仍然可能具有循环控制流;未嵌套在另一个循环内的循环仍然可能是外部循环的一部分;并且在其中一个包含在另一个循环中的任意两个循环之间可能存在其他环。但是,LLVM 环 涵盖了循环和不可约控制流。
FixIrreducible Pass 可以通过插入新的循环头部将不可约控制流转换为循环。它不包含在任何默认优化 Pass 管道中,但某些后端目标需要它。
退出边不是跳出循环的唯一方法。其他可能性包括不可达的终止符、[[noreturn]] 函数、异常、信号和计算机的电源按钮。
“在”循环“内部”且没有返回循环的路径(即到锁存器或头部)的基本块不被视为循环的一部分。以下代码说明了这一点。
for (unsigned i = 0; i <= n; ++i) {
if (c1) {
// When reaching this block, we will have exited the loop.
do_something();
break;
}
if (c2) {
// abort(), never returns, so we have exited the loop.
abort();
}
if (c3) {
// The unreachable allows the compiler to assume that this will not rejoin the loop.
do_something();
__builtin_unreachable();
}
if (c4) {
// This statically infinite loop is not nested because control-flow will not continue with the for-loop.
while(true) {
do_something();
}
}
}
控制流没有最终离开循环的要求,即循环可以是无限的。静态无限循环是没有退出边的循环。动态无限循环有退出边,但有可能永远不会被执行。这可能仅在某些情况下发生,例如当代码中的 n == UINT_MAX 时。
for (unsigned i = 0; i <= n; ++i)
body(i);
优化器可以将动态无限循环转换为静态无限循环,例如,当它可以证明退出条件始终为假时。由于永远不会执行退出边,因此优化器可以将条件分支更改为无条件分支。
如果循环使用 llvm.loop.mustprogress 元数据进行注释,则编译器允许假设它最终会终止,即使它无法证明这一点。例如,即使程序可能永远停留在该循环中,它也可能会删除主体中没有任何副作用的 mustprogress 循环。C 和 C++ 等语言对于某些循环具有此类前向进度保证。另请参阅 mustprogress 和 willreturn 函数属性,以及较旧的 llvm.sideeffect 内在函数。
循环头部在离开循环之前执行的次数是循环迭代次数(或迭代计数)。如果循环根本不应执行,则循环守卫必须跳过整个循环

由于循环头部可能做的第一件事是检查是否还有另一次执行,如果没有,则立即退出而不做任何工作(另请参阅 旋转循环),因此循环迭代次数不是衡量循环迭代次数的最佳指标。例如,对于非正数 n(在循环旋转之前)的以下代码,头部执行次数为 1,即使循环体根本没有执行。
for (int i = 0; i < n; ++i)
body(i);
更好的度量是回边执行计数,它是循环之前执行任何回边的次数。对于进入头部的执行,它比迭代次数少一次。
LoopInfo¶
LoopInfo 是获取循环信息的关键分析。上述定义的一些关键含义对于成功使用此接口非常重要。
LoopInfo 不包含有关非循环环的信息。因此,它不适用于任何需要完整环检测以确保正确性的算法。
LoopInfo 提供了一个接口,用于枚举所有顶层循环(例如,那些不包含在任何其他循环中的循环)。从那里,您可以遍历以该顶层循环为根的子循环树。
在优化期间变为静态不可达的循环必须从 LoopInfo 中删除。如果由于某种原因无法做到这一点,则要求优化保留循环的静态可达性。
循环简化形式¶
循环简化形式是一种规范形式,它使多个分析和转换更简单、更有效。它由 LoopSimplify (-loop-simplify) Pass 确保,并在调度 LoopPass 时由 Pass 管理器自动添加。此 Pass 在 LoopSimplify.h 中实现。当它成功时,循环具有
前置头部。
单个回边(这意味着只有一个锁存器)。
专用出口。也就是说,循环的任何出口块都没有循环外部的前驱。这意味着所有出口块都由循环头部支配。
循环闭合 SSA (LCSSA)¶
如果程序采用 SSA 形式,并且在循环中定义的所有值仅在该循环内部使用,则该程序处于循环闭合 SSA 形式。
以 LLVM IR 编写的程序始终采用 SSA 形式,但不一定采用 LCSSA 形式。为了实现后者,对于每个跨循环边界存活的值,在每个出口块中插入单入口 PHI 节点[1],以便在循环内“闭合”这些值。特别是,考虑以下循环
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2); // X3 defined
}
... = X3 + 4; // X3 used, i.e. live
// outside the loop
在内部循环中,X3 在循环内部定义,但在循环外部使用。在循环闭合 SSA 形式中,这将表示为如下
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
X4 = phi(X3);
... = X4 + 4;
这仍然是有效的 LLVM;额外的 phi 节点是纯粹冗余的,但所有 LoopPass 都需要保留它们。此形式由 LCSSA (-lcssa) Pass 确保,并在调度 LoopPass 时由 LoopPassManager 自动添加。在循环优化完成后,这些额外的 phi 节点将由 -instcombine 删除。
请注意,出口块位于循环外部,那么这样的 phi 如何“闭合”循环内部的值,因为它在循环外部使用它?首先,对于 phi 节点,如 LangRef 中所述:“每个传入值的使用都被认为发生在从相应的前驱块到当前块的边上”。现在,到出口块的边被认为在循环外部,因为如果我们采用该边,它会清楚地将我们引出循环。
但是,边实际上不包含任何 IR,因此在源代码中,我们必须选择一个约定,即使用发生在当前块还是在前驱块中。对于 LCSSA 的目的,我们认为使用发生在后者中(以便将使用视为内部)[2]。
LCSSA 的主要好处是它使许多其他循环优化更简单。
首先,一个简单的观察是,如果需要查看所有外部用户,他们可以只迭代出口块中的所有(循环闭合)PHI 节点(另一种方法是扫描循环中所有指令的 def-use 链[3])。
然后,例如考虑 simple-loop-unswitch 上面的循环。因为它采用 LCSSA 形式,我们知道在循环内部定义的任何值都将仅在循环内部或循环闭合 PHI 节点中使用。在这种情况下,唯一的循环闭合 PHI 节点是 X4。这意味着我们可以只复制循环并相应地更改 X4,如下所示
c = ...;
if (c) {
for (...) {
if (true)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
} else {
for (...) {
if (false)
X1' = ...
else
X2' = ...
X3' = phi(X1', X2');
}
}
X4 = phi(X3, X3')
现在,X4 的所有使用都将获得更新后的值(一般来说,如果循环采用 LCSSA 形式,在任何循环转换中,我们只需要更新循环闭合 PHI 节点即可使更改生效)。如果我们没有循环闭合 SSA 形式,这意味着 X3 可能在循环外部使用。因此,我们将不得不引入 X4(它是新的 X3)并将 X3 的所有使用替换为它。但是,我们应该注意到,由于 LLVM 为每个 Value 保留了 def-use 链[3],我们不需要执行数据流分析来查找和替换所有使用(甚至有一个实用函数 replaceAllUsesWith(),它通过迭代 def-use 链来执行此转换)。
另一个重要的优势是归纳变量的所有使用的行为都是相同的。如果没有这个,您需要区分变量在定义它的循环外部使用的情况,例如
for (i = 0; i < 100; i++) {
for (j = 0; j < 100; j++) {
k = i + j;
use(k); // use 1
}
use(k); // use 2
}
从具有正常 SSA 形式的外部循环来看,k 的第一次使用行为不端,而第二次使用是基数为 100,步长为 1 的归纳变量。虽然在实践中和 LLVM 上下文中,此类情况可以通过 SCEV 有效处理。标量演化 (scalar-evolution) 或 SCEV,是一个(分析)Pass,用于分析和分类循环中标量表达式的演化。
一般来说,在采用 LCSSA 形式的循环中使用 SCEV 更容易。SCEV 可以分析的标量(循环变体)表达式的演化,根据定义,是相对于循环的。表达式在 LLVM 中由 llvm::Instruction 表示。如果表达式在两个(或更多)循环内(这只能在循环嵌套时发生,如上面的示例所示),并且您想获得对其演化(来自 SCEV)的分析,则还必须指定相对于哪个循环。具体来说,您必须使用 getSCEVAtScope()。
但是,如果所有循环都采用 LCSSA 形式,则每个表达式实际上由两个不同的 llvm::Instruction 表示。一个在循环内部,一个在循环外部,它是循环闭合 PHI 节点,表示表达式在最后一次迭代后的值(实际上,我们将每个循环变体表达式分解为两个表达式,因此,每个表达式最多在一个循环中)。您现在可以只使用 getSCEV()。并且您传递给它的这两个 llvm::Instruction 中的哪一个消除了上下文/作用域/相关循环的歧义。
脚注
“更规范”的循环¶
旋转循环¶
循环通过 LoopRotate (loop-rotate) Pass 旋转,该 Pass 将循环转换为 do/while 样式循环,并在 LoopRotation.h 中实现。示例
void test(int n) {
for (int i = 0; i < n; i += 1)
// Loop body
}
被转换为
void test(int n) {
int i = 0;
do {
// Loop body
i += 1;
} while (i < n);
}
警告:此转换仅在编译器可以证明循环体将至少执行一次时才有效。否则,它必须插入一个守卫,在运行时对其进行测试。在上面的示例中,这将是
void test(int n) {
int i = 0;
if (n > 0) {
do {
// Loop body
i += 1;
} while (i < n);
}
}
理解循环旋转在 LLVM IR 级别的效果非常重要。我们继续使用 LLVM IR 中的先前示例,同时还提供控制流图 (CFG) 的图形表示。您可以通过使用 view-cfg Pass 获得相同的图形结果。
最初的 for 循环可以转换为
define void @test(i32 %n) {
entry:
br label %for.header
for.header:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
%cond = icmp slt i32 %i, %n
br i1 %cond, label %body, label %exit
body:
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
br label %for.header
exit:
ret void
}
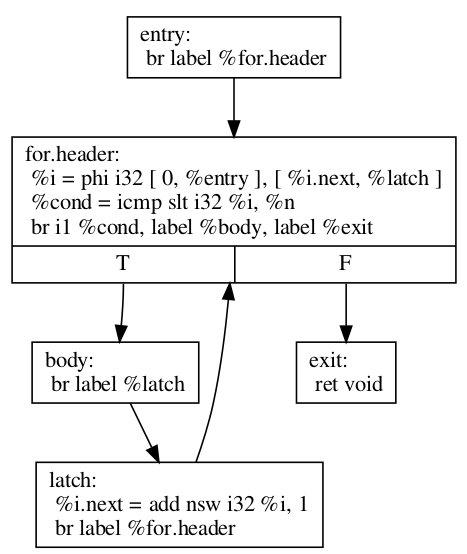
在我们解释 LoopRotate 实际上将如何转换此循环之前,下面是我们如何(手动)将其转换为 do-while 样式循环。
define void @test(i32 %n) {
entry:
br label %body
body:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %exit
exit:
ret void
}
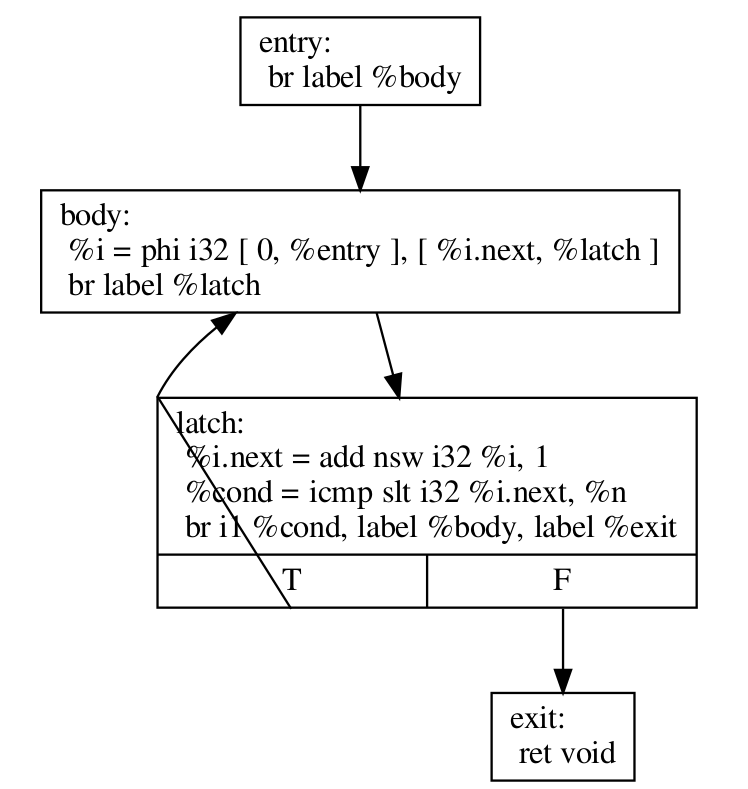
注意两点
条件检查已移至循环的“底部”,即锁存器。这是 LoopRotate 通过将循环的头部复制到锁存器来完成的。
在这种情况下,编译器无法推断出循环肯定会至少执行一次,因此上述转换无效。如上所述,必须插入一个守卫,这是 LoopRotate 将要做的。
这是 LoopRotate 转换此循环的方式
define void @test(i32 %n) {
entry:
%guard_cond = icmp slt i32 0, %n
br i1 %guard_cond, label %loop.preheader, label %exit
loop.preheader:
br label %body
body:
%i2 = phi i32 [ 0, %loop.preheader ], [ %i.next, %latch ]
br label %latch
latch:
%i.next = add nsw i32 %i2, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %loop.exit
loop.exit:
br label %exit
exit:
ret void
}
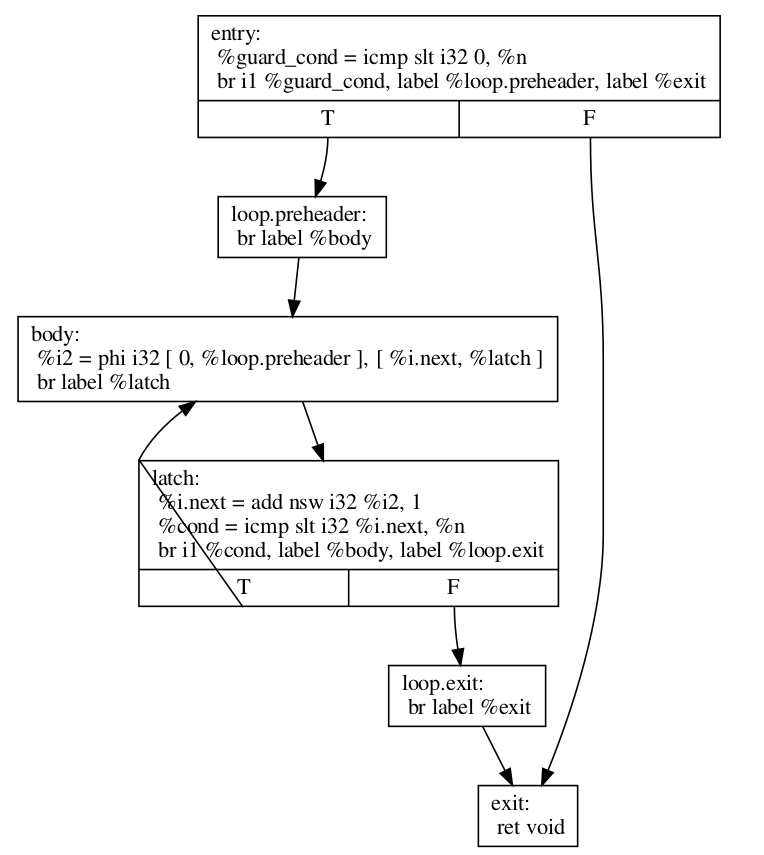
结果比我们预期的要复杂一些,因为 LoopRotate 确保循环在旋转后处于 循环简化形式。在这种情况下,它插入了 %loop.preheader 基本块,以便循环具有前置头部,并引入了 %loop.exit 基本块,以便循环具有专用出口(否则,%exit 将从 %latch 和 %entry 跳转,但 %entry 不包含在循环中)。请注意,循环也必须预先处于循环简化形式,LoopRotate 才能成功应用。
这种形式的主要优点是它允许将不变指令(尤其是加载)提升到前置头部。这也可以在非旋转循环中完成,但有一些缺点。让我们用一个例子来说明它们
for (int i = 0; i < n; ++i) {
auto v = *p;
use(v);
}
我们假设从 p 加载是不变的,use(v) 是使用 v 的某些语句。如果我们只想执行一次加载,我们可以将其“移出”循环体,从而得到如下结果
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
但是,现在,在 n <= 0 的情况下,在初始形式中,循环体永远不会执行,因此,加载永远不会执行。这主要是语义原因的问题。考虑 n <= 0 且从 p 加载无效的情况。在初始程序中,不会出现错误。但是,通过这种转换,我们将引入一个错误,从而有效地破坏初始语义。
为了避免这两个问题,我们可以插入一个守卫
if (n > 0) { // loop guard
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
}
这当然更好,但可以稍微改进一下。请注意,检查 n 是否大于 0 执行了两次(并且 n 在两者之间没有变化)。一次是在我们检查守卫条件时,一次是在循环的第一次执行中。为了避免这种情况,我们可以进行无条件的第一次执行,并将循环条件插入到末尾。这实际上意味着将循环转换为 do-while 循环
if (0 < n) {
auto v = *p;
do {
use(v);
++i;
} while (i < n);
}
请注意,LoopRotate 通常不进行此类提升。相反,它是其他 Pass(如循环不变代码移动 (-licm))的启用转换。