推测加载硬化¶
Spectre 变体 #1 缓解技术¶
作者:Chandler Carruth - chandlerc@google.com
问题陈述¶
最近,谷歌 Project Zero 和其他研究人员通过利用现代 CPU 中的推测执行发现了信息泄露漏洞。这些漏洞目前分为三个变体
GPZ 变体 #1(又名 Spectre 变体 #1):边界检查(或谓词)绕过
GPZ 变体 #2(又名 Spectre 变体 #2):分支目标注入
GPZ 变体 #3(又名 Meltdown):恶意数据缓存加载
有关更多详细信息,请参阅 Google Project Zero 博客文章和 Spectre 研究论文
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
https://spectreattack.com/spectre.pdf
GPZ 变体 #1 的核心问题是,推测执行使用分支预测来选择推测执行的指令路径。此路径使用可用数据进行推测执行,并且可能会从内存加载并通过各种侧信道泄漏加载的值,即使推测执行因不正确而被撤销,这些侧信道仍然存在。错误预测的路径可能导致代码使用永远不会在正确执行中发生的数据输入来执行,从而使针对恶意输入的检查无效,并允许攻击者使用恶意数据输入来泄漏秘密数据。这是一个示例,从 Project Zero 论文中提取并简化而来
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...; // small array
struct array *arr2 = ...; // array of size 0x400
unsigned long untrusted_offset_from_caller = ...;
if (untrusted_offset_from_caller < arr1->length) {
unsigned char value = arr1->data[untrusted_offset_from_caller];
unsigned long index2 = ((value&1)*0x100)+0x200;
unsigned char value2 = arr2->data[index2];
}
攻击的关键是在分支预测器预测它将在范围内时,使用远远超出范围的 untrusted_offset_from_caller 调用此函数。在这种情况下,if 的主体将被推测执行,并且可能会将秘密数据读取到 value 中,并在对 value2 进行依赖访问以填充它时,通过缓存计时侧信道泄漏它。
高级缓解方法¶
虽然正在积极寻求几种方法来缓解特定分支和/或尤其危险的软件(最值得注意的是各种操作系统内核)内部的加载,但这些方法需要手动和/或静态分析辅助的代码审计以及显式源代码更改才能应用缓解措施。它们不太可能很好地扩展到大型应用程序。我们正在提出一种全面的缓解方法,该方法将在整个程序中自动应用,而不是通过手动更改代码。虽然这可能会带来很高的性能成本,但某些应用程序可能非常适合接受这种性能/安全权衡。
我们提出的具体技术是使用无分支代码检查加载,以确保它们沿着有效的控制流路径执行。考虑以下 C 伪代码,它表示谓词保护潜在无效加载的核心思想
void leak(int data);
void example(int* pointer1, int* pointer2) {
if (condition) {
// ... lots of code ...
leak(*pointer1);
} else {
// ... more code ...
leak(*pointer2);
}
}
这将转换为类似于以下内容
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
if (condition) {
// Assuming ?: is implemented using branchless logic...
predicate_state = !condition ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
} else {
predicate_state = condition ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
}
}
结果应该是,如果 if (condition) { 分支被错误预测,则存在对用于将任何指针归零的数据依赖关系,然后再通过它们加载,或者将所有加载的位归零。即使此代码模式可能仍然会推测执行,无效的 推测执行也会被阻止从内存中泄漏秘密数据(但请注意,此数据可能仍以安全的方式加载,并且某些内存区域被要求不保存秘密,请参阅下面的详细限制)。这种方法仅要求底层硬件有一种方法来实现寄存器值的无分支和不可预测的条件更新。所有现代架构都支持这一点,事实上,这种支持对于正确实现恒定时间加密原语是必要的。
此方法的关键属性
它并没有阻止任何特定的侧信道工作。这很重要,因为存在未知数量的潜在侧信道,并且我们希望继续发现更多。相反,它首先阻止了秘密数据的观察。
它累积谓词状态,即使在嵌套的正确预测的控制流面前也能提供保护。
它跨越函数边界传递此谓词状态,以提供跨过程保护。
在硬化加载的地址时,它使用地址的破坏性或不可逆修改,以防止攻击者使用攻击者控制的输入来反转检查。
它不会完全阻止推测执行,而只是阻止错误推测的路径从内存中泄漏秘密(并暂停推测,直到可以确定这一点)。
它是完全通用的,除了能够执行无分支条件数据更新和缺乏值预测之外,它对底层架构没有任何基本假设。
它不需要程序员使用静态源代码注释或容易受到变体 #1 样式攻击的代码来识别所有可能的秘密数据。
此方法的局限性
它需要重新编译源代码以插入硬化指令序列。只有以这种模式编译的软件才能受到保护。
性能在很大程度上取决于特定架构的实现策略。我们在下面概述了一个潜在的 x86 实现,并描述了其性能。
它不能防御已经从内存加载并驻留在寄存器中或通过非推测执行中的其他侧信道泄漏的秘密数据。处理此问题的代码(例如加密例程)已经使用恒定时间算法和代码来防止侧信道。此类代码还应在以下操作后清除寄存器中的秘密数据:这些指南。
为了获得合理的性能,许多加载可能不会被检查,例如那些具有编译时固定地址的加载。这主要包括对全局变量和局部变量的编译时常数偏移量的访问。需要此保护并有意存储秘密数据的代码必须确保用于秘密数据的内存区域是必要的动态映射或堆分配。这是一个可以调整的区域,以提供更全面的保护,但会牺牲性能。
硬化的加载可能仍然从有效地址加载数据(如果不是攻击者控制的地址)。为了防止这些地址读取秘密数据,应保护地址空间的低 2gb 以及任何可执行页面上方和下方 2gb 的空间。
致谢
通过数据跟踪错误推测并标记指针以阻止错误推测加载的核心思想是在 Chandler Carruth、Paul Kocher、Thomas Pornin 和其他几个人之间的 HACS 2018 讨论中提出的。
屏蔽加载位的核心思想是 Jann Horn 在报告这些攻击时提出的原始缓解措施的一部分。
间接分支、调用和返回¶
可以使用变体 #1 样式的错误预测来攻击条件分支以外的控制流。
对虚拟方法的热调用目标的预测可能导致在使用预期类型时对其进行推测执行(通常称为“类型混淆”)。
由于预测,可能会推测执行热案例,而不是作为跳转表实现的 switch 语句的正确案例。
从函数返回时,可能会错误地预测热常用返回地址。
这些代码模式也容易受到 Spectre 变体 #2 的攻击,因此最好在 x86 平台上使用 retpoline 进行缓解。当使用像 retpoline 这样的缓解技术时,推测根本无法通过间接控制流边缘进行(或者在填充 RSB 的情况下无法错误预测),因此它也受到变体 #1 样式攻击的保护。但是,某些架构、微架构或供应商不采用 retpoline 缓解措施,并且在未来的 x86 硬件(Intel 和 AMD)上,由于基于硬件的缓解措施,预计 retpoline 缓解措施将变得不必要。
当不使用 retpoline 时,这些边缘将需要独立于变体 #1 样式攻击的保护。用于条件控制流的类似方法应该有效
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
switch (condition) {
case 0:
// Assuming ?: is implemented using branchless logic...
predicate_state = (condition != 0) ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
break;
case 1:
predicate_state = (condition != 1) ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
break;
// ...
}
}
核心思想仍然相同:使用数据流验证控制流,并使用该验证来检查加载是否无法沿着错误推测的路径泄漏信息。通常,这涉及跨边缘传递此类控制流的预期目标,并在之后检查其是否正确。请注意,虽然很容易认为这可以缓解变体 #2 攻击,但事实并非如此。这些攻击会转到不包含检查的任意小工具。
变体 #1.1 和 #1.2 攻击:“边界检查绕过存储”¶
除了核心变体 #1 攻击之外,还有扩展此攻击的技术。主要技术被称为“边界检查绕过存储”,并在本研究论文中讨论:https://people.csail.mit.edu/vlk/spectre11.pdf
我们将独立分析这两个变体。首先,变体 #1.1 通过在边界检查绕过之后推测性地存储在返回地址上来工作。然后,CPU 在返回的推测执行期间最终使用此推测存储,这可能会将推测执行定向到二进制文件中的任意小工具。让我们看一个例子。
unsigned char local_buffer[4];
unsigned char *untrusted_data_from_caller = ...;
unsigned long untrusted_size_from_caller = ...;
if (untrusted_size_from_caller < sizeof(local_buffer)) {
// Speculative execution enters here with a too-large size.
memcpy(local_buffer, untrusted_data_from_caller,
untrusted_size_from_caller);
// The stack has now been smashed, writing an attacker-controlled
// address over the return address.
minor_processing(local_buffer);
return;
// Control will speculate to the attacker-written address.
}
但是,可以通过像硬化任何其他加载一样硬化返回地址的加载来缓解这种情况。这有时很复杂,因为例如 x86 隐式地从堆栈加载返回地址。但是,下面的实现技术专门设计用于通过使用堆栈指针在函数之间传递错误推测来缓解此隐式加载。这另外导致错误推测具有无效的堆栈指针,并且永远无法读取推测性存储的返回地址。请参阅下面的详细讨论。
对于变体 #1.2,攻击者推测性地存储到用于实现间接调用或间接跳转的 vtable 或跳转表中。因为这是推测性的,所以即使它们存储在只读页面中,通常也是可能的。例如
class FancyObject : public BaseObject {
public:
void DoSomething() override;
};
void f(unsigned long attacker_offset, unsigned long attacker_data) {
FancyObject object = getMyObject();
unsigned long *arr[4] = getFourDataPointers();
if (attacker_offset < 4) {
// We have bypassed the bounds check speculatively.
unsigned long *data = arr[attacker_offset];
// Now we have computed a pointer inside of `object`, the vptr.
*data = attacker_data;
// The vptr points to the virtual table and we speculatively clobber that.
g(object); // Hand the object to some other routine.
}
}
// In another file, we call a method on the object.
void g(BaseObject &object) {
object.DoSomething();
// This speculatively calls the address stored over the vtable.
}
缓解这种情况需要硬化来自这些位置的加载,或缓解间接调用或间接跳转。任何这些都足以阻止调用或跳转使用已读回的推测性存储值。
对于这两种情况,使用 retpoline 也同样足够。一种可能的混合方法是为间接调用和跳转使用 retpoline,同时依靠 SLH 来缓解返回。
另一种对这两种情况都足够的方法是硬化所有推测性存储。但是,由于大多数存储都不有趣并且本质上不会泄漏数据,因此考虑到它所防御的攻击,预计这将非常昂贵。
实现细节¶
有许多复杂的细节会影响此技术的实现,无论是在特定架构上还是在特定编译器中。我们讨论了 x86 架构和 LLVM 编译器的建议实现技术。这些主要用作示例,因为其他实现技术非常有可能。
x86 实现细节¶
在 x86 平台上,我们将实现分解为三个核心组件:通过控制流图累积谓词状态、检查加载以及检查过程之间的控制转移。
累积谓词状态¶
考虑如下所示的基线 x86 指令,这些指令测试三个条件,如果全部通过,则从内存加载数据,并可能通过某些侧信道泄漏数据
# %bb.0: # %entry
pushq %rax
testl %edi, %edi
jne .LBB0_4
# %bb.1: # %then1
testl %esi, %esi
jne .LBB0_4
# %bb.2: # %then2
testl %edx, %edx
je .LBB0_3
.LBB0_4: # %exit
popq %rax
retq
.LBB0_3: # %danger
movl (%rcx), %edi
callq leak
popq %rax
retq
当我们去推测执行加载时,我们想知道是否任何动态执行的谓词被错误推测。为了跟踪这一点,沿着每个条件边缘,我们需要跟踪允许采取该边缘的数据。在 x86 上,此数据存储在条件跳转指令使用的标志寄存器中。沿着控制流中此分支之后的两个边缘,标志寄存器保持活动状态,并包含我们可以用来构建累积谓词状态的数据。我们使用 x86 条件移动指令累积它,该指令也读取状态所在的标志寄存器。已知这些条件移动指令在任何 x86 处理器上都不会被预测,这使得它们免受可能重新引入漏洞的错误预测。当我们插入条件移动时,代码最终看起来像这样
# %bb.0: # %entry
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
testl %edi, %edi
jne .LBB0_1
# %bb.2: # %then1
cmovneq %r8, %rax # Conditionally update predicate state.
testl %esi, %esi
jne .LBB0_1
# %bb.3: # %then2
cmovneq %r8, %rax # Conditionally update predicate state.
testl %edx, %edx
je .LBB0_4
.LBB0_1:
cmoveq %r8, %rax # Conditionally update predicate state.
popq %rax
retq
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
...
在这里,我们通过将 %rax 归零来创建“空”或“正确执行”谓词状态,并通过将 -1 放入 %r8 来创建一个常量“不正确执行”谓词值。然后,沿着从条件分支出来的每个边缘,我们执行条件移动,在正确的执行中,这将是一个空操作,但如果错误推测,则会将 %rax 替换为 %r8 的值。错误推测三个谓词中的任何一个都会导致 %rax 从 %r8 中保存“不正确执行”值,因为我们在执行正确时保留传入值,而不是覆盖它。
我们现在在每个基本块中的 %rax 中有一个值,指示之前在某个时候是否错误预测了谓词。并且我们安排了该值在下面用于硬化加载时特别有效。
间接调用、分支和返回谓词¶
在跟踪间接调用、分支和返回时,没有类似的标志可以使用。谓词状态必须通过其他方式累积。从根本上说,这与 CFI 中提出的问题相反:我们需要检查我们来自哪里,而不是我们要去哪里。对于函数本地跳转表,这很容易安排,方法是在每个目标中测试跳转表的输入(尚未实现,请使用 retpoline)
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
jmpq *.LJTI0_0(,%rdi,8) # Indirect jump through table.
.LBB0_2: # %sw.bb
testq $0, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_3: # %sw.bb1
testq $1, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_5: # %sw.bb10
testq $2, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
...
.section .rodata,"a",@progbits
.p2align 3
.LJTI0_0:
.quad .LBB0_2
.quad .LBB0_3
.quad .LBB0_5
...
返回在 x86-64 上有一种简单的缓解技术(或其他具有所谓的“红色区域”的 ABI,该区域超出堆栈末尾)。保证此区域在中断和上下文切换之间保持不变,从而使返回到当前代码中使用的返回地址保留在堆栈上并且可以读取。我们可以在调用者中发出代码来验证返回边缘是否未被错误预测
callq other_function
return_addr:
testq -8(%rsp), return_addr # Validate return address.
cmovneq %r8, %rax # Update predicate state.
对于没有“红色区域”的 ABI(因此无法从堆栈中读取返回地址),我们可以在调用之前将预期的返回地址计算到跨调用保留的寄存器中,并以类似于上述方式使用它。
间接调用(以及在没有红色区域 ABI 的情况下的返回)对传播提出了最重大的挑战。最简单的技术是定义一个新的 ABI,以便将预期的调用目标传递到被调用函数并在入口处进行检查。不幸的是,新的 ABI 在 C 和 C++ 中部署起来非常昂贵。虽然目标函数可以在 TLS 中传递,但我们仍然需要复杂的逻辑来处理使用和不使用此额外逻辑编译的函数的混合(本质上,使 ABI 向后兼容)。目前,我们建议在此处使用 retpoline,并将继续研究缓解这种情况的方法。
优化、替代方案和权衡¶
仅仅累积谓词状态就涉及大量成本。我们采用了几个关键优化来最大限度地减少这一点,并且各种替代方案在生成的代码中呈现出不同的权衡。
首先,我们努力减少用于跟踪状态的指令数量
我们不是在原始程序中的每个条件边缘都插入
cmovCC指令,而是跟踪在进入每个基本块之前我们需要捕获的每组条件标志,并为这些标志重用一个通用的cmovCC序列。当需要多个
cmovCC指令来捕获标志集时,我们可以进一步重用后缀。目前,人们认为这不值得付出代价,因为成对的标志相对罕见,而它们的后缀则极其罕见。
x86 中的一个常见模式是有多个条件跳转指令使用相同的标志但处理不同的条件。天真地,我们可以将它们之间的每个直通都视为一个“边缘”,但这会导致更复杂的控制流图。相反,我们累积直通所需的条件集,并在单个直通边缘中使用一系列
cmovCC指令来跟踪它。
其次,我们通过为“坏”状态分配一个寄存器来权衡寄存器压力以获得更简单的 cmovCC 指令。我们可以从内存中读取该值作为条件移动指令的一部分,但是,这会创建更多的微操作,并需要加载-存储单元参与。目前,我们将该值放入虚拟寄存器中,并允许寄存器分配器决定寄存器压力何时足以使其值得溢出到内存并重新加载。
硬化加载¶
一旦我们将谓词累积到一个特殊值中,用于区分正确与错误推测,我们就需要将其应用于加载,以确保它们不会泄漏秘密数据。对此有两种主要技术:我们可以硬化加载的值以防止观察,或者我们可以硬化地址本身以防止加载发生。这些技术具有显着不同的性能权衡。
硬化加载的值¶
硬化加载的最吸引人的方法是屏蔽所有加载的位。关键要求是,对于加载的每个位,沿着错误推测的路径,该位始终固定为 0 或 1,而与加载的位的值无关。最明显的实现是使用 and 指令,在错误推测的路径上使用全零掩码,在正确的路径上使用全一掩码,或者使用 or 指令,在错误推测的路径上使用全一掩码,在正确的路径上使用全零掩码。其他选项变得不太有吸引力,例如乘以零或多个移位指令。出于我们在下面详细说明的原因,我们最终建议您使用 or 和全一掩码,使 x86 指令序列看起来像这样
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
movl (%rsi), %edi # Load potentially secret data from %rsi.
orl %eax, %edi
其他有用的模式可能是将加载折叠到 or 指令本身中,但代价是寄存器到寄存器的复制。
部署此方法存在一些挑战
x86 上的许多加载都折叠到其他指令中。分离它们将增加非常显着且代价高昂的寄存器压力,并带来令人望而却步的性能成本。
加载可能不以通用寄存器为目标,需要额外的指令将状态值映射到正确的寄存器类,并且可能需要更昂贵的指令以某种方式屏蔽该值。
x86 上的标志寄存器很可能处于活动状态,并且廉价地保留它们具有挑战性。
加载的值比用于加载的指针和索引多得多。因此,硬化加载的结果比硬化加载的地址需要更多的指令(请参见下文)。
尽管存在这些挑战,但硬化加载的结果至关重要地允许加载继续进行,因此对执行的总推测/乱序潜力的影响要小得多。还有几种有趣的技术可以尝试缓解这些挑战,并使硬化加载结果至少在某些情况下可行。但是,我们通常希望在从硬化加载的值到硬化地址本身的下一种方法时回退(如果无利可图)。
折叠到数据不变操作中的加载可以在操作后硬化¶
使这成为可行的第一个关键是认识到 x86 上的许多操作都是“数据不变的”。也就是说,它们没有(已知的)可观察的行为差异,这是由于特定的输入数据造成的。这些指令通常在实现处理私钥数据的加密原语时使用,因为人们认为它们不提供任何侧信道。同样,我们可以将硬化推迟到它们之后,因为它们本身不会引入推测执行侧信道。这导致代码序列看起来像
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
orl %eax, %edi
虽然对加载的(可能是秘密的)值进行了加法运算,但这不会泄漏任何数据,然后我们立即对其进行硬化。
加载值的硬化推迟到数据不变表达式图的下方¶
我们可以概括之前的想法,并将硬化下沉到表达式图中,跨越尽可能多的数据不变操作。这可以对某些东西是否是数据不变的采用非常保守的规则。主要目标应该是使用单个硬化指令处理多个加载
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
addl 4(%rsi), %edi # Continue without leaking.
addl 8(%rsi), %edi
orl %eax, %edi # Mask out bits from all three loads.
在 Haswell、Zen 和更新的处理器上保留标志,同时硬化加载的值¶
遗憾的是,x86 上没有有用的指令可以在不触及标志寄存器的情况下将掩码应用于所有 64 位。但是,我们可以通过将值零扩展到完整字大小,然后使用 BMI2 shrx 指令右移至少原始位数,来硬化窄于字的值(32 位系统上少于 32 位,64 位系统上少于 64 位)
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate 32 bits of data.
shrxq %rax, %rdi, %rdi # Shift out all 32 bits loaded.
由于在 x86 上零扩展是免费的,因此可以有效地硬化加载的值。
硬化加载的地址¶
当硬化加载的值不适用时,最常见的原因是指令直接泄漏信息(如 cmp 或 jmpq),我们切换到硬化加载的地址而不是加载的值。这避免了通过展开加载或支付其他高成本来增加寄存器压力。
要了解这在实践中是如何工作的,我们需要检查 x86 寻址模式的确切语义,其完全通用形式如下所示:(%base,%index,scale)offset。这里,%base 和 %index 是 64 位寄存器,它们可能是任何值,并且可能由攻击者控制,而 scale 和 offset 是固定的立即值。scale 必须是 1、2、4 或 8,并且 offset 可以是任何 32 位符号扩展值。然后,找到地址的确切计算是:%base + (scale * %index) + offset 在 64 位 2 的补码模算术下。
这种方法的一个问题是,在硬化之后,`%base + (scale *
然后,一个大的正 offset 将索引到地址空间的前两个千兆字节内的内存中。虽然这些偏移量不受攻击者控制,但攻击者可以选择攻击恰好具有所需偏移量的加载,然后成功读取该区域中的内存。这大大增加了攻击者的负担,并限制了攻击范围,但并未消除它。为了完全消除攻击,我们必须与操作系统合作,以排除在地址空间的低两个千兆字节中映射内存。
64 位加载检查指令¶
我们可以使用以下指令序列来检查加载。在这些示例中,我们将 %r8 设置为保存 -1 的特殊值,该值将在错误推测的路径中通过 cmov 移动到 %rax 上。
单寄存器寻址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
movl (%rsi), %edi
双寄存器寻址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
orq %rax, %rcx # Mask the index if misspeculating.
movl (%rsi,%rcx), %edi
这将导致接近零的负地址或在 offset 中将地址空间包装回小的正地址。对于大多数操作系统,小的负地址将在用户模式下出错,但需要高地址空间可供用户访问的目标可能需要调整上面使用的确切序列。此外,低地址需要由操作系统标记为不可读,以完全硬化加载。
RIP 相对寻址甚至更容易破解¶
有一种常见的寻址模式习惯用法,更难检查:相对于指令指针的寻址。我们无法更改指令指针寄存器的值,因此我们遇到了更难的问题,即通过仅更改 %index 来强制 %base + scale * %index + offset 成为无效地址。我们拥有的唯一优势是攻击者也无法修改 %base。如果我们使用上面的快速指令序列,但仅将其应用于索引,我们将始终访问 %rip + (scale * -1) + offset。如果攻击者可以找到一个加载,该加载的地址恰好指向秘密数据,那么他们就可以访问它。但是,加载器和基本库也可以简单地拒绝在程序中任何文本的 2gb 范围内映射堆、数据段或堆栈,就像它可以保留地址空间的低 2gb 一样。
标志寄存器再次使一切变得困难¶
不幸的是,使用 orq-指令的技术在 x86 上有一个严重的缺陷。使状态易于累积的东西,即包含谓词的标志寄存器,在这里引起了严重的问题,因为它们可能处于活动状态并被加载指令或后续指令使用。在 x86 上,orq 指令设置标志,并将覆盖已有的任何内容。这使得将它们插入到指令流中非常危险。不幸的是,与硬化加载的值不同,我们在这里没有后备方案,因此我们必须有一种完全通用的方法可用。
生成这些序列时,我们必须做的第一件事是尝试分析周围的代码,以证明标志实际上不是活动的或正在使用。通常,它是由某些其他指令设置的,这些指令恰好设置了标志寄存器(很像我们的!),而没有实际的依赖关系。在这些情况下,直接插入这些指令是安全的。或者,我们可以将它们提前移动以避免破坏使用的值。
但是,这最终可能是不可能的。在这种情况下,我们需要在这些指令周围保留标志
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
pushfq
orq %rax, %rcx # Mask the pointer if misspeculating.
orq %rax, %rdx # Mask the index if misspeculating.
popfq
movl (%rcx,%rdx), %edi
使用 pushf 和 popf 指令将标志寄存器保存在我们插入的代码周围,但这会带来很高的成本。首先,我们必须将标志存储到堆栈并重新加载它们。其次,这会导致堆栈指针动态调整,需要使用帧指针来引用溢出到堆栈等的临时变量。
在较新的 x86 处理器上,我们可以使用 lahf 和 sahf 指令将除溢出标志之外的所有标志保存在寄存器中,而不是在堆栈上。然后,我们可以使用 seto 和 add 在寄存器中保存和恢复溢出标志。结合起来,这将以与上述相同的方式保存和恢复标志,但使用两个寄存器而不是堆栈。在大多数情况下,即使比 pushf 和 popf 稍微便宜一些,这仍然非常昂贵。
Haswell、Zen 和更新处理器上的无标志替代方案¶
从 Haswell 和 Zen 处理器上提供的 BMI2 x86 指令集扩展开始,有一种用于移位的指令不设置任何标志:shrx。我们可以使用它和 lea 指令来实现类似于上述那些指令序列的代码序列。但是,这些指令仍然只是略微慢一些,因为在大多数现代 x86 处理器中,能够调度移位指令的端口比 or 指令的端口少。
快速、单寄存器寻址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shrxq %rax, %rsi, %rsi # Shift away bits if misspeculating.
movl (%rsi), %edi
这将把寄存器折叠为零或一,并将寻址模式中除偏移量之外的所有内容折叠为小于或等于 9。这意味着完整地址只能保证小于 (1 << 31) + 9。操作系统可能希望保护额外的低地址空间页以应对这种情况
优化¶
这种方法的大部分成本来自以这种方式检查加载,因此优化这一点非常重要。然而,除了使应用检查的指令序列高效之外(例如,通过避免 pushfq 和 popfq 序列),唯一重要的优化是减少检查的加载次数,同时不引入漏洞。我们应用了几种技术来实现这一点。
不要检查来自编译时常量堆栈偏移的加载¶
我们在 x86 上实现此优化,方法是跳过检查使用固定帧指针偏移的加载。
此优化的结果是,像重新加载溢出寄存器或访问全局字段这样的模式不会被检查。这是一个非常显著的性能提升。
不要检查依赖加载¶
这种缓解策略之所以奏效,核心部分原因在于它在加载的地址上建立了数据流检查。然而,这意味着如果地址本身已经使用经过检查的加载加载,则无需检查依赖加载,只要它与经过检查的加载在同一个基本块内,因此没有额外的谓词保护它。考虑如下代码
...
.LBB0_4: # %danger
movq (%rcx), %rdi
movl (%rdi), %edx
这将转换为
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rcx # Mask the pointer if misspeculating.
movq (%rcx), %rdi # Hardened load.
movl (%rdi), %edx # Unhardened load due to dependent addr.
这不会检查通过 %rdi 的加载,因为该指针已经依赖于经过检查的加载。
使用单个 lfence 保护大型、加载密集型代码块¶
在代码块的开头使用单个 lfence 指令可能值得,该代码块以大量需要独立保护且需要强化加载地址的加载开始。然而,这在实践中不太可能有利可图。强化的延迟损失需要超过正确推测执行时 lfence 的延迟损失。但在这种情况下,lfence 的成本是推测执行的完全损失(至少)。到目前为止,我们获得的关于使用 lfence 的性能成本的证据表明,很少有(如果有的话)热代码模式可以使这种权衡变得有意义。
打破安全模型的诱人优化¶
考虑了几种优化,但由于未能坚持安全模型而失败。特别值得讨论其中一种,因为许多其他优化都会归结为它。
我们想知道是否可以只检查基本块中的第一个加载。如果检查按预期工作,它会形成一个无效指针,甚至无法在硬件中进行虚拟地址转换。它应该在其处理过程中很早就发生故障。也许这会在推测路径未能泄漏任何秘密之前及时阻止事情发生。但这最终行不通,因为处理器本质上是乱序执行的,即使在其推测域中也是如此。因此,攻击者可能会导致初始地址计算本身停顿,并允许任意数量的不相关加载(包括攻击秘密数据的加载)通过。
过程间检查¶
现代 x86 处理器可能会推测进入被调用函数和从函数推测到其返回地址。因此,我们需要一种方法来检查在推测错误的谓词之后发生的加载,但加载和推测错误的谓词位于不同的函数中。本质上,我们需要谓词状态跟踪的某种过程间泛化。在函数之间传递谓词状态的主要挑战是我们不希望为了使这种缓解措施更易于部署而需要更改 ABI 或调用约定,并且进一步希望以这种方式缓解的代码可以很容易地与未以这种方式缓解的代码混合,而不会完全失去缓解措施的价值。
将谓词状态嵌入到堆栈指针的高位¶
我们可以使用允许强化指针的相同技术,将谓词状态传入和传出函数。堆栈指针在函数之间很容易传递,我们可以测试它是否设置了高位,以检测它何时因推测错误而被标记。调用点指令序列如下所示(假设推测错误状态值为 -1)
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
这首先将谓词状态放入 %rsp 的高位,然后再调用函数,然后在之后从 %rsp 的高位读取出来。当正确执行(推测或非推测)时,这些都是空操作。当推测错误时,堆栈指针最终将变为负数。我们安排它保持规范地址,但其他方面保持低位不变,以允许堆栈调整正常进行,而不会破坏这一点。在被调用函数内部,我们可以提取此谓词状态,然后在返回时重置它
other_function:
# prolog
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
# ...
.LBB0_N:
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
retq
当所有代码都以这种方式缓解时,这种方法是有效的,甚至可以幸存于非常有限地进入未缓解的代码(状态将在未缓解的函数中来回传递,只是不会更新)。但它确实有一些限制。将状态合并到 %rsp 中是有成本的,并且它不会将缓解的代码与未缓解的调用者中的推测错误隔离开来。
使用这种形式的过程间缓解也有一个优势:通过形成这些无效的堆栈指针地址,我们可以防止推测返回成功读取推测写入到实际堆栈的值。这首先通过在计算堆栈上返回地址的地址和我们的谓词状态之间形成数据依赖性来实现。即使满足了条件,如果误预测导致状态中毒,则生成的堆栈指针将无效。
重写内部函数的 API 以直接传播谓词状态¶
(尚未实施。)
我们可以在内部函数中选择直接调整其 API 以接受谓词作为参数并返回它。这可能比嵌入到 %rsp 中进入函数略微便宜。
使用 lfence 来保护函数转换¶
可以使用 lfence 指令来防止后续加载在所有先前的误预测谓词都解决之前进行推测执行。我们可以使用这个更广泛的屏障来阻止函数之间执行的推测加载。我们在入口块中发出它以处理调用,并在每次返回之前发出它。当与未缓解的代码混合时,这种方法还具有提供最强缓解程度的优势,即通过停止所有进入已缓解函数的误预测,而不管调用者中发生了什么。然而,这种混合本质上更具风险。这种混合是否足以进行缓解需要仔细分析。
不幸的是,实验结果表明,对于某些代码模式,这种方法的性能开销非常高。一个经典的例子是任何形式的递归评估引擎。当使用 lfence 进行缓解时,热、快速的调用和返回序列表现出显著的性能损失。仅此组件就可能使性能倒退 2 倍或更多,即使仅在代码混合中使用,这也使其成为一种令人不快的权衡。
使用内部 TLS 位置来传递谓词状态¶
我们可以定义一个特殊的线程本地值来保存函数之间的谓词状态。这通过使用调用者和被调用者之间的侧通道来传递谓词状态,从而避免了直接的 ABI 影响。它还允许状态的隐式零初始化,这允许非检查代码成为第一个执行的代码。
然而,这需要在入口块中从 TLS 加载,在每次调用和每次 ret 之前存储到 TLS,以及在每次调用之后从 TLS 加载。因此,即使与在函数入口块中使用 %rsp 甚至 lfence 相比,预计它的成本也会高得多。
定义新的 ABI 和/或调用约定¶
我们可以定义新的 ABI 和/或调用约定,以显式地传入和传出函数中的谓词状态。如果所有替代方案的性能都不够,这可能会很有趣,但这会使部署和采用变得非常复杂,并且可能不可行。
高级替代缓解策略¶
对于缓解变体 1 攻击,还有完全不同的替代方法。大多数 讨论 到目前为止,都集中在通过手动重写代码以包含不易受攻击的指令序列来缓解 Linux 内核(或其他内核)中特定的已知可攻击组件。对于 x86 系统,这是通过在如果推测执行会泄漏数据的代码路径上注入 lfence 指令,或者通过重写内存访问以对已知安全区域进行无分支屏蔽来完成的。在 Intel 系统上,lfence 将阻止秘密数据的推测加载。在 AMD 系统上,lfence 目前是空操作,但可以通过设置 MSR 使其成为调度序列化操作,从而排除代码路径的推测错误(缓解措施 G-2 + V1-1)。
然而,这依赖于查找和枚举代码中所有可能被攻击以泄漏信息的点。虽然在某些情况下,静态分析可以有效地大规模完成这项工作,但在许多情况下,它仍然依赖于人为判断来评估代码是否可能容易受到攻击。特别是对于那些接受不太详细审查但仍然对这些攻击敏感的软件系统,这似乎是一种不切实际的安全模型。我们需要一种自动和系统的缓解策略。
条件边缘上的自动 lfence¶
扩展现有手工编码缓解措施的一种自然方法是简单地将 lfence 指令注入到每个条件分支的目标和 fallthrough 目标中。这确保了没有谓词或边界检查可以被推测性地绕过。然而,这种方法的性能开销简直是灾难性的。然而,它仍然是这项工作之前已知的唯一真正“默认安全”的方法,并且是性能的基准。
为了解决这种方法的性能开销并使其更实际地部署,一种尝试是 MSVC 的 /Qspectre 开关。他们的技术是在编译器内使用静态分析,仅在有攻击风险的条件边缘插入 lfence 指令。然而,初步 分析 表明,这种方法是不完整的,并且仅捕获了少数且有限的可攻击模式子集,这些模式恰好非常接近初始的概念验证。因此,虽然其性能是可以接受的,但它似乎不是一种充分的系统缓解措施。
性能开销¶
这种全面缓解风格的性能开销非常高。然而,与之前推荐的方法(例如 lfence 指令)相比,它非常有利。正如用户可以限制 lfence 的范围以控制其性能影响一样,这种缓解技术也可以在范围内受到限制。
然而,重要的是要了解获得完全缓解的基线需要付出什么代价。在这里,我们假设目标是 Haswell(或更新版本)处理器,并使用所有技巧来提高性能(因此将低 2gb 保持不受保护,并将程序中任何 PC 周围的 +/- 2gb 保持不受保护)。我们运行了 Google 的微基准测试套件和一个使用 ThinLTO 和 PGO 构建的大型高度优化的服务器。所有这些都是使用 -march=haswell 构建的,以便访问 BMI2 指令,并且基准测试是在大型 Haswell 服务器上运行的。我们收集了基于 lfence 的缓解措施和此处介绍的加载强化措施的数据。总结是,使用加载强化进行缓解比使用 lfence 进行缓解快 1.77 倍,并且与正常程序相比,加载强化的开销可能在 10% 到 50% 之间,大多数大型应用程序的开销为 30% 或更低。
基准测试 |
|
加载强化 |
缓解加速 |
|---|---|---|---|
Google 微基准测试套件 |
-74.8% |
-36.4% |
2.5 倍 |
大型服务器 QPS(使用 ThinLTO & PGO) |
-62% |
-29% |
1.8 倍 |
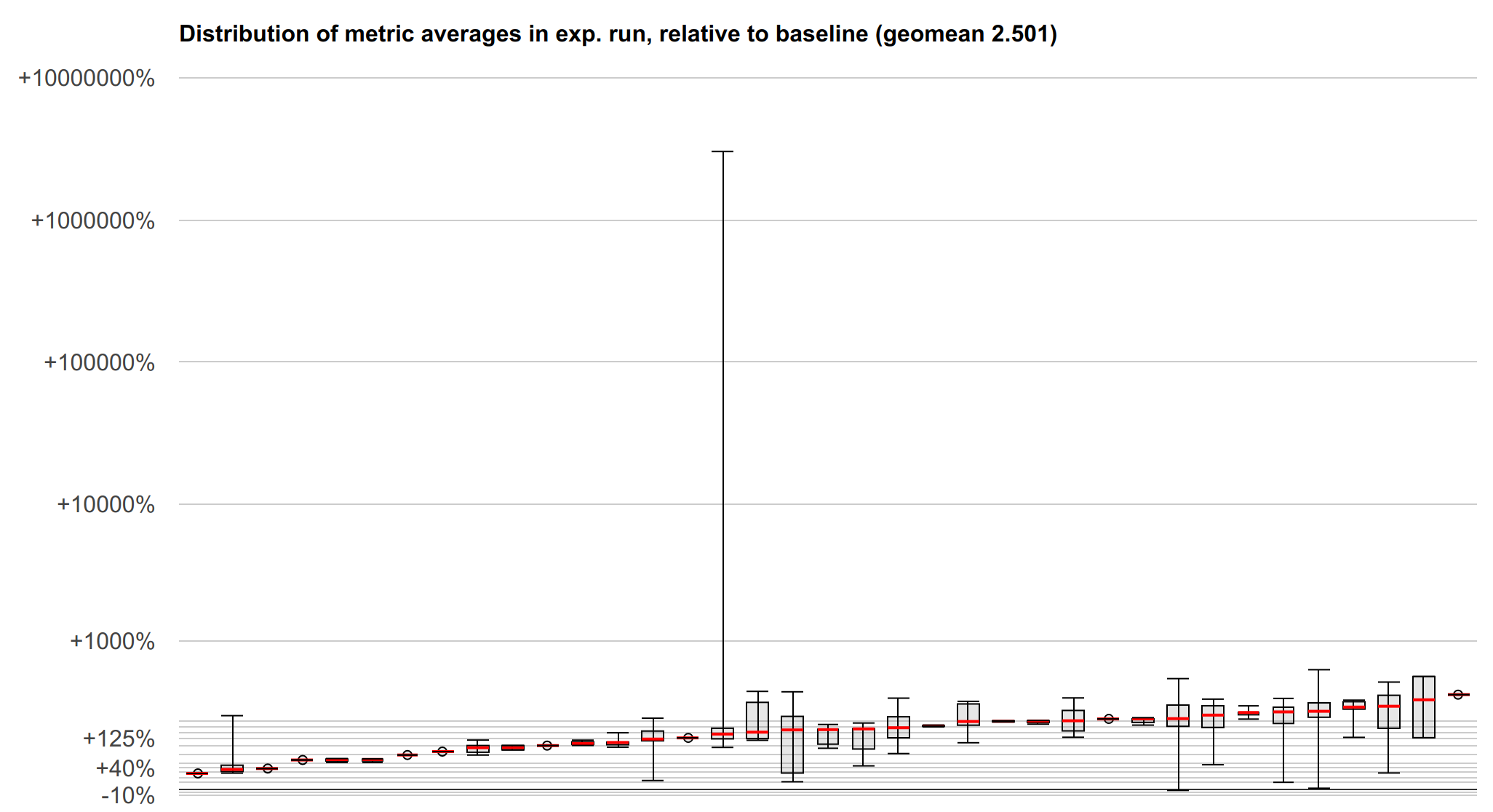
下面是微基准测试套件结果的可视化,它有助于显示结果的分布,而这种分布在摘要中有些丢失。y 轴是加载强化相对于 lfence 的对数刻度加速比(向上 -> 更快 -> 更好)。每个箱线图代表一个微基准测试,该基准测试可能测量了许多不同的指标。红线标记中位数,箱子标记第一个和第三个四分位数,须线标记最小值和最大值。
我们还没有关于 SPEC 或 LLVM 测试套件的基准测试数据,但我们可以努力获取这些数据。尽管如此,以上内容应该清楚地描述了性能特征,并且特定基准测试不太可能揭示特别有趣的属性。
未来工作:细粒度控制和 API 集成¶
这种技术的性能开销可能非常显著,用户希望控制或减少这种开销。这里有一些有趣的选项会影响所使用的实施策略。
一个特别有吸引力的选择是在相当精细的粒度上(例如,在每个函数的基础上)允许选择加入和选择退出这种缓解措施,包括智能处理内联决策——受保护的代码可以防止内联到未受保护的代码中,而未受保护的代码在内联到受保护的代码中时将变为受保护的代码。对于只有有限的代码集可以通过外部控制输入访问的系统,可能可以通过此类机制限制缓解范围,而不会损害应用程序的整体安全性。性能影响也可能集中在少数关键函数中,这些函数可以通过性能开销较低的手动缓解方法进行缓解,而应用程序的其余部分则接受自动保护。
对于限制缓解范围或手动缓解热函数,需要一些支持来混合缓解和未缓解的代码,而不会完全破坏缓解措施。对于第一种用例,特别希望缓解的代码在从未缓解的代码进行推测错误调用时仍然安全。
对于第二种用例,将自动缓解技术连接到显式缓解 API(例如 http://wg21.link/p0928 中描述的 API(或任何其他最终 API))可能很重要,以便有一种干净的方法从自动缓解切换到手动缓解,而不会立即暴露漏洞。然而,在 API 得到更好的建立之前,很难提出如何做到这一点的设计。我们将随着这些 API 的成熟而重新审视这一点。