在big endian模式下使用ARM NEON指令¶
简介¶
为 big endian ARM 处理器生成代码在很大程度上是直接的。 然而,NEON 加载和存储具有一些有趣的特性,这使得在 big endian 模式下代码生成决策不太明显。
本文档旨在解释 NEON 加载和存储的问题,以及 LLVM 中已实现的解决方案。
在本文档中,“向量”一词指的是 ARM ABI 所谓的“短向量”,它是一个可以容纳在 NEON 寄存器中的项目序列。 此序列的长度可以是 64 位或 128 位,并且可以构成 8 位、16 位、32 位或 64 位项目。 本文档通篇引用 A64 指令,但几乎也适用于 A32/ARMv7 指令集。 A32 中传递向量的 ABI 格式与 A64 略有不同。 除此之外,相同的概念适用。
示例:C 级内联函数 -> 汇编¶
首先说明 C 级 ARM NEON 内联函数如何降低为指令可能会有所帮助。
这个简单的 C 函数接受一个包含四个整数的向量,并将第零个 lane 设置为值 “42”
#include <arm_neon.h>
int32x4_t f(int32x4_t p) {
return vsetq_lane_s32(42, p, 0);
}
arm_neon.h 内联函数尽可能生成“通用” IR(即,正常的 IR 指令而不是 llvm.arm.neon.* 内联函数调用)。 上述代码生成了
define <4 x i32> @f(<4 x i32> %p) {
%vset_lane = insertelement <4 x i32> %p, i32 42, i32 0
ret <4 x i32> %vset_lane
}
然后变成以下简单的汇编
f: // @f
movz w8, #0x2a
ins v0.s[0], w8
ret
问题¶
主要问题是向量在内存和寄存器中的表示方式。
首先,回顾一下。 项目的“endianness”仅影响其在内存中的表示。 在寄存器中,数字只是一系列位 - 在 AArch64 通用寄存器的情况下为 64 位。 然而,内存是大小为 8 位的可寻址单元序列。 因此,任何大于 8 位的数字都必须分成 8 位块,而 endianness 描述了这些块在内存中布局的顺序。
“little endian” 布局的最低有效字节在前(内存地址最低)。 “big endian” 布局的最高有效字节在前。 这意味着当从 big endian 内存加载项目时,内存中最低的 8 位必须进入最高的 8 位,依此类推。
LDR 和 LD1¶
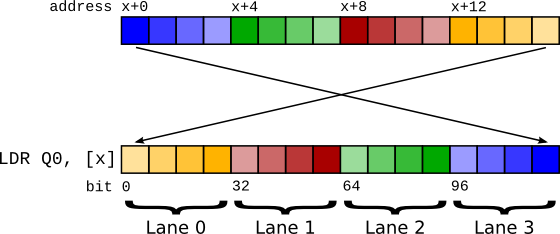
图 1 使用 LDR 的 Big endian 向量加载。¶
向量是同时操作的连续项目序列。 要加载 64 位向量,需要从内存中读取 64 位。 在 little endian 模式下,我们可以通过执行 64 位加载来做到这一点 - LDR q0, [foo]。 然而,如果我们尝试在 big endian 模式下执行此操作,由于字节交换,lane 索引最终会被交换! 内存中布局的第零个项目变为向量中的第 n 个 lane。
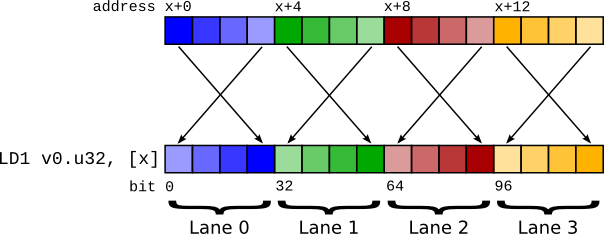
图 2 使用 LD1 的 Big endian 向量加载。 请注意,lane 保留了正确的顺序。¶
因此,指令 LD1 执行向量加载,但不是对整个 64 位执行字节交换,而是对向量内的各个项目执行字节交换。 这意味着寄存器内容与在 little endian 系统上相同。
似乎 LD1 应该足以在 big endian 机器上执行向量加载。 然而,这两种方法各有优缺点,使得选择哪种寄存器格式变得不那么简单。
有两种选择
向量寄存器的内容与使用
LDR指令加载时的内容相同。向量寄存器的内容与使用
LD1指令加载时的内容相同。
因为 LD1 == LDR + REV,类似地 LDR == LD1 + REV(在 big endian 系统上),我们可以用另一种类型的加载加上 REV 指令来模拟任何一种类型的加载。 因此,我们不是在决定使用哪些指令,而是在决定使用哪种格式(这将影响哪种指令最适合使用)。
请注意,在本节中,我们仅提及加载。 存储与其关联的加载具有完全相同的问题,因此为了简洁起见已跳过。
考量¶
LLVM IR Lane 排序¶
LLVM IR 具有第一类向量类型。 在 LLVM IR 中,向量的第零个元素驻留在最低内存地址。 优化器在某些领域依赖于此属性,例如在将向量连接在一起时。 其目的是使数组和向量具有相同的内存布局 - [4 x i8] 和 <4 x i8> 应该在内存中以相同的方式表示。 如果没有此属性,优化器将不得不巧妙地处理许多特殊情况。
使用 LDR 会破坏此 lane 排序属性。 这并不排除使用 LDR,但我们必须执行以下两项操作之一
在每次
LDR之后插入REV指令以反转 lane 顺序。禁用所有依赖于 lane 布局的优化,并对于每次访问单个 lane (
insertelement/extractelement/shufflevector) 时反转 lane 索引。
AAPCS¶
ARM 程序调用标准 (AAPCS) 定义了在寄存器中函数之间传递向量的 ABI。 它指出
当短向量在寄存器和内存之间传输时,它被视为不透明对象。 也就是说,短向量存储在内存中,就好像它是使用整个寄存器的单个
STR存储的一样; 短向量是使用相应的LDR指令从内存加载的。 在 little-endian 系统上,这意味着元素 0 将始终包含短向量的最低寻址元素; 在 big-endian 系统上,元素 0 将包含短向量的最高寻址元素。—ARM 64 位架构 (AArch64) 的程序调用标准,4.1.2 短向量
使用 ABI 定义的 LDR 和 STR 至少比 LD1 和 ST1 有一个优势。 LDR 和 STR 不知道向量的各个 lane 的大小。 LD1 和 ST1 则不是 - lane 大小编码在其中。 这在 ABI 边界上很重要,因为有必要知道被调用者期望的 lane 宽度。 考虑以下代码
<callee.c>
void callee(uint32x2_t v) {
...
}
<caller.c>
extern void callee(uint32x2_t);
void caller() {
callee(...);
}
如果 callee 将其签名更改为 uint16x4_t,这在寄存器内容中是等效的,如果我们作为 LD1 传递,我们将破坏此代码,直到 caller 被更新和重新编译。
有一种观点认为,如果两个函数的签名不同,则行为应该是未定义的。 但是,可能存在一些函数对向量的 lane 布局不可知,并且在 ABI 边界上没有通用格式的情况下,将向量视为不透明值(仅加载和存储它)是不可能的。
因此,为了保持 ABI 兼容性,我们需要在函数调用中使用 LDR lane 布局。
对齐¶
在严格对齐模式下,LDR qX 要求其地址为 128 位对齐,而 LD1 仅要求其与 lane 大小对齐。 如果我们规范化为使用 LDR,我们仍然需要在某些地方使用 LD1 以避免对齐错误(LD1 的结果然后需要用 REV 反转)。
然而,大多数操作系统不会启用对齐错误运行,因此这通常不是问题。
总结¶
下表总结了对于上述提到的每个属性,两种解决方案中的每一种都需要发出的指令。
|
|
|
|---|---|---|
Lane 排序 |
|
|
AAPCS |
|
|
严格模式下的对齐 |
|
|
这两种方法都不是完美的,选择一种方法归结为选择两害相权取其轻。 决定 lane 排序问题必须更改目标无关的编译器 pass,并导致 lane 索引反转的奇怪 IR。 决定这比必须进行更改以支持 LD1 更糟糕,因此选择 LD1 作为规范向量加载指令(并因此推断,ST1 用于向量存储)。
实现¶
实现分为 3 个部分
谓词
LDR和STR指令,以便永远不允许选择它们来生成向量加载和存储。 例外是单 lane 向量[1] - 这些根据定义不可能存在 lane 排序问题,因此可以使用LDR/STR。为位转换创建代码生成模式,以创建
REV指令。确保创建适当的位转换,以便向量值作为 1 元素向量(这与使用
LDR加载时相同)在调用边界上传递。
位转换¶
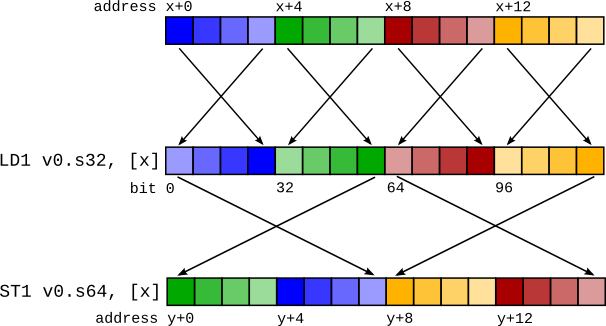
LD1 解决方案的主要问题是处理位转换(或位播,或重新解释转换)。 这些是伪指令,仅更改编译器对数据的解释,而不是底层数据本身。 一个要求是,如果数据被加载然后再次保存(称为“往返”),则存储后的内存内容应与加载前相同。 如果加载向量,然后在存储之前将其位转换为不同的向量类型,则往返当前将被破坏。
以以下代码序列为例
%0 = load <4 x i32> %x
%1 = bitcast <4 x i32> %0 to <2 x i64>
store <2 x i64> %1, <2 x i64>* %y
这将生成如图右侧所示的代码序列。 不匹配的 LD1 和 ST1 导致存储的数据与加载的数据不同。
当我们看到从类型 X 到类型 Y 的位播时,我们需要做的是更改数据的寄存器内表示,使其好像刚刚被类型为 Y 的 LD1 加载一样。
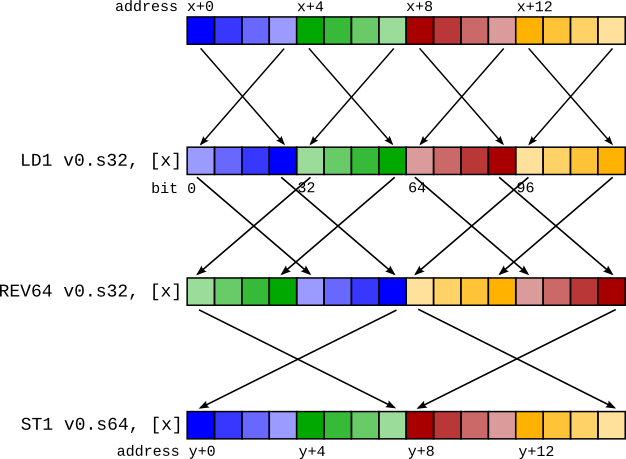
从概念上讲,这很简单 - 我们可以插入一个 REV 来撤消类型为 X 的 LD1(将寄存器内表示转换为与使用 LDR 加载时相同),然后插入另一个 REV 以更改表示,使其好像已被类型为 Y 的 LD1 加载一样。
对于前面的示例,这将是
LD1 v0.4s, [x]
REV64 v0.4s, v0.4s // There is no REV128 instruction, so it must be synthesizedcd
EXT v0.16b, v0.16b, v0.16b, #8 // with a REV64 then an EXT to swap the two 64-bit elements.
REV64 v0.2d, v0.2d
EXT v0.16b, v0.16b, v0.16b, #8
ST1 v0.2d, [y]
事实证明,这些 REV 对几乎在所有情况下都可以压缩成单个 REV。 对于上面的示例,REV128 4s + REV128 2d 实际上是 REV64 4s,如图右侧所示。